April 18, 2025
Distributed Tracing at Scale: Keeping It Useful in Microservice Chaos

Chintan Viradiya
Author

Nandini Parekh
Contributor

Rakshit Menpara
Reviewer
Distributed Tracing at Scale: Keeping It Useful in Microservice Chaos
Distributed tracing has become a critical component of microservice-based architectures, especially when organizations scale their systems to handle millions of transactions across various services. As services become increasingly complex, tracing becomes an essential tool to monitor and troubleshoot performance issues, identify bottlenecks, and understand the intricate interactions between services. However, the challenges of keeping distributed tracing useful as systems scale are significant and multifaceted.
What Distributed Tracing Is in a Microservice Environment
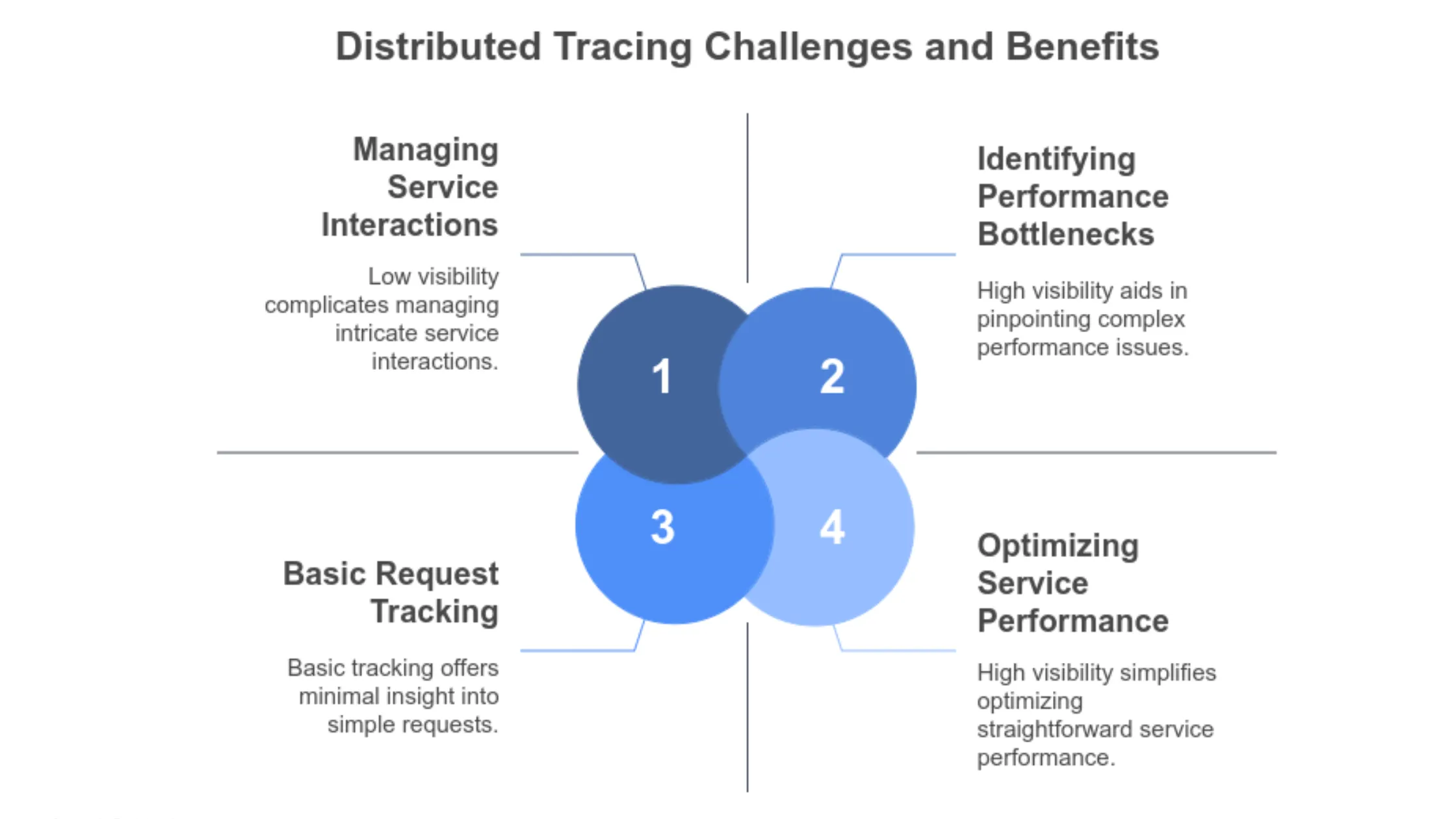
Distributed tracing is a method of tracking the flow of requests as they traverse multiple microservices. At a high level, it allows you to trace the execution path of a request through the different services in an architecture, providing visibility into how the system is functioning. The core of distributed tracing relies on the concept of a trace, which represents the journey of a request. This trace is subdivided into spans, with each span representing the work done by a particular service or operation. The trace captures details such as the start and end times of each span, the duration, and metadata about the request, all of which are valuable for understanding performance and identifying issues.
In a microservices environment, distributed tracing is crucial for understanding how various services interact and where the performance bottlenecks are. However, achieving effective distributed tracing at scale presents unique challenges.
Challenges in Distributed Tracing at Scale
Data Volume and Overhead
One of the primary challenges when scaling distributed tracing is managing the sheer volume of trace data generated. In a system with hundreds or thousands of microservices, each service might generate traces for every request it handles. These traces contain a significant amount of metadata, which can grow exponentially as the system scales.
The volume of data can overwhelm storage and analysis systems, leading to performance degradation in both the tracing system and the services themselves. In some cases, the overhead of collecting and transmitting trace data can introduce latency, thereby affecting the very performance that tracing is supposed to monitor.
To mitigate this, sampling strategies are often employed to limit the amount of data collected. Sampling involves capturing only a subset of all the traces, typically based on certain criteria (e.g., request rate, error rate, or specific endpoints). While this reduces the overhead of tracing, it also introduces the risk of missing important insights, particularly for low-frequency issues or edge cases that might only appear in a small number of requests.
Complexity of Trace Collection
In a microservice environment, different services may be implemented using different programming languages, frameworks, and technologies. The instrumentation required to capture trace data must be compatible with all these different technologies. Implementing distributed tracing in a system where services vary widely in terms of the tech stack is inherently complex.
Many microservices are ephemeral, often deployed in containers or serverless environments, which adds another layer of complexity. Ensuring that trace data is consistently collected, even in highly dynamic environments, requires robust instrumentation that can handle the transient nature of modern services.
This complexity can lead to incomplete or inaccurate trace data, especially when services are added, removed, or updated frequently. Tracing systems must evolve to ensure they can collect and correlate trace data across a diverse set of services without missing critical context.
Correlating Distributed Traces
In large-scale microservice systems, the same request may pass through dozens or even hundreds of microservices. These services may run in different regions, data centers, or cloud environments. Correlating trace data across such a large and diverse system is challenging. Each service may have its own logging and monitoring infrastructure, making it difficult to stitch together a coherent view of the entire trace.
To address this challenge, tracing systems rely on unique identifiers, such as trace IDs and span IDs, to tie together the various spans generated by different services. However, ensuring these identifiers propagate correctly across all services, especially in systems with complex interdependencies, is nontrivial. Mismanagement of trace IDs or failure to propagate them correctly can result in incomplete traces or false conclusions about system behavior.
Furthermore, when the trace spans are distributed across different data centers or cloud providers, network latency and inconsistent time synchronization can lead to discrepancies in trace data. This can make it more difficult to accurately measure the performance of a request as it travels through different services.
Impact of Tracing on Service Performance
As mentioned earlier, tracing introduces some level of overhead. In high-performance systems, even a small amount of overhead can be significant. The act of capturing trace data involves recording timestamps, adding metadata, and transmitting information to a centralized tracing system. In highly concurrent environments, the act of logging trace data can result in contention, which, in turn, leads to increased latency.
Some tracing systems use a pull model, where the trace data is periodically fetched from services, while others use a push model, where services push their trace data to a central collector. Each model has its trade-offs in terms of performance impact, and careful consideration is needed to choose the right approach for a given architecture.
In some scenarios, the tracing data itself can become a bottleneck if the collection infrastructure is not scaled appropriately. This is particularly true when dealing with a high volume of low-latency transactions, where the overhead of trace collection can significantly impact throughput.
Security and Privacy Concerns
Distributed tracing involves the collection of metadata, which can sometimes contain sensitive information, such as user IDs, transaction IDs, or internal business data. Managing trace data in a way that ensures privacy and compliance with data protection regulations (e.g., GDPR, CCPA) is critical.
As systems scale, it becomes increasingly difficult to enforce strict controls over what data is captured and who has access to it. Unnecessary exposure of sensitive data through traces can lead to security vulnerabilities or compliance violations. To address this, organizations must ensure that only relevant information is captured in traces and that the trace data is properly encrypted during transmission and storage.
Data Retention and Query Performance
As the number of traces collected increases, storing and querying that data becomes a significant challenge. Many distributed tracing systems store traces in distributed databases or time-series data stores. These databases need to scale effectively to handle the high write throughput required by a large-scale tracing system.
In addition, querying traces to identify performance bottlenecks or errors requires fast access to large amounts of data. As the volume of trace data grows, ensuring that the querying performance does not degrade is a critical consideration. Techniques such as indexing, partitioning, and sharding must be implemented to ensure that the tracing system can handle high query loads while maintaining low latency.
Conclusion
Poorly managed distributed tracing at scale introduces multiple risks. Without full trace coverage, diagnosing performance issues becomes difficult, delaying root cause analysis and extending outages. Inefficient trace pipelines can add overhead, degrading service performance and undermining observability goals. Incomplete or misconfigured traces lead to incorrect conclusions, triggering false alarms or masking real failures.
Unprotected trace data increases exposure to privacy and security violations, especially when sensitive information is embedded in spans. Effective tracing at scale requires disciplined configuration, performance-aware infrastructure, and strict data governance—otherwise, tracing may introduce more complexity than value.
Frequently Asked Question
Get quick answers to common queries. Explore our FAQs for helpful insights and solutions.
Distributed tracing is an observability technique used to track a single request as it flows through multiple services, systems, and components in a distributed architecture. It helps teams understand request latency, dependencies, and failure points across microservices.
As systems grow in complexity, failures and performance issues rarely originate from a single service. Distributed tracing provides end-to-end visibility, making it possible to diagnose latency bottlenecks, cascading failures, and cross-service dependencies that are otherwise invisible.
Logs provide detailed event records, and metrics show aggregated trends over time. Distributed tracing connects individual events and metrics across services into a single request journey, enabling precise root-cause analysis instead of guesswork.
- High and unpredictable latency
- Difficult root-cause analysis
- Poor visibility into service dependencies
- Debugging issues across async and distributed workflows
- Mean time to resolution (MTTR) challenges
Trace sampling controls how many requests are traced and stored. It is essential at scale to balance observability depth with cost and system performance. Intelligent sampling focuses on slow, failed, or anomalous requests instead of tracing everything.
Written by
Chintan Viradiya
Chintan Viradiya is a DevOps Engineer at Improwised Technologies. Passionate about Infrastructure as Code and CI/CD pipelines, he focuses on optimizing cloud deployments and enhancing the security and performance of modern applications. He plays a key role in ensuring high availability and driving DevOps best practices across projects


March 25, 2026
Secure Intra-Cluster Networking in Kubernetes Through WireGuard
Chintan Viradiya
Author

February 12, 2026
DevSecOps Architecture Explained: Security as Code, Policy Automation, and GitOps
Chintan Viradiya
Author


January 22, 2026
FluxCD with Helm: Scaling Platform Governance via GitOps Reconciliation
Chintan Viradiya
Author
Optimize Your Cloud. Cut Costs. Accelerate Performance.
Struggling with slow deployments and rising cloud costs?
Our tailored platform engineering solutions enhance efficiency, boost speed, and reduce expenses.