January 22, 2026
FluxCD with Helm: Scaling Platform Governance via GitOps Reconciliation

Chintan Viradiya
Author

Shyam Kapdi
Contributor

Rakshit Menpara
Reviewer
A lack of tools rarely causes infrastructure delivery failures. They are usually the result of uncontrolled change propagation as systems grow in complexity, teams scale, and release frequency increases. At this stage, the core problem is no longer deployment speed - it is how change is governed, reconciled, and corrected over time.
This is where FluxCD with Helm should be understood as an operating model, not a CI/CD toolchain upgrade.
Helm standardizes application packaging through versioned charts and dependencies, but it remains an imperative mechanism - changes occur only when someone runs a command or pipeline. FluxCD, in contrast, enforces declarative state reconciliation, continuously aligning the actual cluster state with the desired state defined in Git.
By combining Flux’s source-controller and helm-controller, Helm releases become a continuously reconciled system of intent rather than one-time deployment actions. Git becomes the single source of truth, and any drift - manual, accidental, or environmental - is automatically detected and corrected.
This is why FluxCD + Helm must be designed, not merely installed. It defines how change enters the platform, how it propagates across environments, and how operational stability is preserved. At scale, reliability is achieved not by more controls, but by systems that continuously correct themselves by design.
This article focuses on that distinction - explaining not just what FluxCD with Helm does, but why it fundamentally reshapes ownership models, risk boundaries, and reliability guarantees in modern platform engineering.
The Real Problem Enterprises Face (That Helm or CI/CD Alone Can’t Solve)
As enterprises scale their Kubernetes adoption, most delivery models still rely on event-driven CI/CD pipelines to apply changes. Pipelines react to commits, build artifacts, and execute deployment steps, but once those steps complete, the system effectively stops thinking about the state it just created. This is the structural limitation that Helm or CI/CD alone cannot address.
Helm releases executed through CI pipelines lack several properties that matter at scale:
-
No drift awareness: After deployment, neither Helm nor the pipeline continuously verifies whether the cluster still matches the intended configuration. Manual fixes, emergency patches, or controller-side mutations silently accumulate.
-
No declarative ownership boundaries: Pipelines apply manifests, but they do not define who owns long-term responsibility for that state, or how competing changes should be resolved.
-
No continuous enforcement: CI enforces correctness only at execution time, not throughout the lifecycle of the workload.
-
No native model for cross-release coordination: Ordering, dependencies, and shared contracts between releases are handled externally, often through fragile scripting or human process.
Over time, teams compensate with manual rollbacks, ad-hoc overrides, and environment-specific hotfixes. These actions may restore short-term stability, but they quietly break system contracts. The cluster drifts away from what Git claims is true, and the organization loses confidence in its own delivery model.
FluxCD fundamentally reframes this problem. Instead of treating deployment as a task to be executed, Flux treats it as a continuous process of desired state convergence. Helm charts are no longer “installed” and forgotten - they are reconciled against declared intent on an ongoing basis. If reality diverges from Git, the system detects and corrects it automatically.
This shift - from event-driven execution to state-driven reconciliation - is the missing layer enterprises need. It is not about replacing Helm or CI, but about addressing the operational gap they were never designed to solve: long-term correctness, consistency, and control of change in a dynamic system.
Also Read: Separating CI and CD: The Key to Faster, Safer Delivery
Why Helm’s Power is Unlocked Inside FluxCD
Used imperatively via a CI script, Helm is a sophisticated package manager. Inside FluxCD, it transforms into a declarative state enforcement engine.
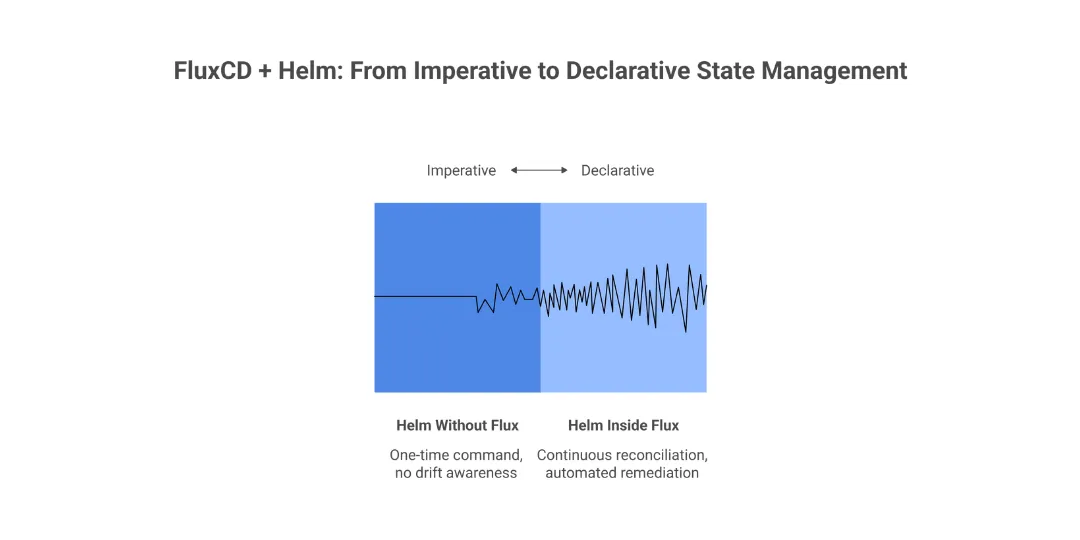
Helm Without Flux (The Imperative Model):
- Imperative Upgrades:
helm upgradeis a one-time command. It offers no protection against subsequent configuration drift. - Environment Glue Code: Teams rely on complex Bash scripts or CI YAML to manage environment-specific
values.yamlfiles, leading to fragility. - Reactive Recovery: Rollbacks require manual intervention or are tied to CI job failures.
Helm Inside Flux (The Declarative Model):
- Versioned Intent (
HelmRelease): The deployment is a persistent, versioned object in Git (e.g., apps/myapp/release.yaml). This makes the desired state auditable and searchable. - Continuous Health Reconciliation: The
helm-controllerensures the cluster state matches your Git repository by reconciling releases via the Helm CLI. While readiness probes are managed at the Kubernetes Deployment level, Flux monitors the underlying resources to confirm a successful rollout. Additionally, Flux can be configured to execute Helm tests immediately following an install or upgrade to validate the release. - Automated Remediation: Flux maintains environment integrity by automatically correcting configuration drift if manual changes occur. For failed upgrades or test regressions, Flux can perform an automated rollback, provided
spec.rollback.enable:trueis defined in theHelmReleaseconfiguration.
Helm ceases to be a mere CLI tool. Inside Flux, it becomes a packaged state definition that the cluster actively self-enforces.
HelmRelease as a Control Contract (Not Just a Manifest)
A HelmRelease custom resource is the cornerstone of this model. It explicitly encodes a control contract:
apiVersion: helm.toolkit.fluxcd.io/v2
kind: HelmRelease
metadata:
name: my-application
namespace: production
spec:
interval: 5m # Reconciliation loop interval
chart:
spec:
chart: my-app-chart # Chart source (managed by source-controller)
version: 1.2.3
values:
replicaCount: 4
image:
tag: v1.2.3-prod
install:
remediation:
retries: 3
upgrade:
remediation:
retries: 3
cleanupOnFail: true
rollback:
enable: true # Automated rollback on failure
test:
enable: true # Run Helm tests after install/upgradeA HelmRelease captures three critical dimensions:
- Desired State
It specifies the exact chart version, source, and configuration values that are allowed to run. Anything outside this definition is treated as drift, not an acceptable variation. - Health Criteria
Readiness conditions, timeouts, and optional test hooks define what “healthy” actually means at runtime - not just whether a deployment command completed successfully. - Automated Remediation
Retry and rollback policies define how the system must respond when expectations are violated, making failure handling deterministic and repeatable.
This approach fundamentally changes how reliability is achieved. By embedding recovery and validation logic directly into HelmRelease definitions, organizations shift from relying on human-driven heroics to achieving policy-driven reliability. Rollbacks become predictable, machine-led actions, and resilience is codified into the platform itself.
At scale, reliability is no longer dependent on operator judgment under pressure - it is enforced continuously through explicit contracts that the system is designed to uphold.
Separation of Concerns: Enabling Organizational Scale
FluxCD with Helm creates clean boundaries that allow platform and application teams to scale effectively.
Platform Team Owns the Infrastructure Contract:
- Standardized Helm Charts: Curated, secure, and compliant charts for common services (e.g., monitoring, ingress).
- Reconciliation Policies: Defining sync intervals, health check standards, and cluster-wide defaults via
Kustomizationresources. - Environment Governance: Managing namespace isolation, resource quotas, and network policies.
- Reconciliation Policies: Defining sync intervals, health check standards, and cluster-wide defaults via
Application Team Owns the Business Intent:
- Configuration (Values): Specifying environment-specific parameters (replica count, environment variables).
- Release Strategy: Controlling the promotion of new versions through Git repository structures (e.g.,
main->productionpath). - Application Health Logic: Defining appropriate readiness and liveness probes within their Helm charts.
- Release Strategy: Controlling the promotion of new versions through Git repository structures (e.g.,
Developers are liberated from “Accidental Ops” and can focus on code, while platform engineers shift from reactive firefighting to proactive platform design. This decoupling is a strategic enabler for the unified repositories and environment consistency that Improwised champions.
Multi-Environment and Multi-Cluster Strategy Without Pipeline Explosion
As environments and clusters multiply, many organizations respond by adding more pipelines, conditionals, and environment-specific logic. This leads to operational sprawl and inconsistent promotion behavior. FluxCD with Helm avoids this by shifting environment management from pipelines to declarative reconciliation.
FluxCD natively supports environment - and cluster-specific reconciliation, allowing each cluster to continuously align itself with the desired state defined in Git. Promotion between environments happens through declarative Git updates, not imperative pipeline execution.
Helm charts remain consistent across environments, while Helm values act as clean configuration overlays rather than branching strategies. This eliminates chart duplication and pipeline complexity.
The leadership impact is significant:
- One consistent delivery model from dev to production
- Fewer pipelines and less orchestration logic
- Fewer environment-specific exceptions
- Fewer outages caused by inconsistent promotion paths
FluxCD and Helm enable multi-environment, multi-cluster delivery, allowing for scaling without turning CI/CD into the system of record.
Drift, Failure, and Recovery as First-Class System Behaviors
In mature distributed systems, drift is not an anomaly - it is an expected outcome of continuous change, controller behavior, and human intervention. The real risk is not drift itself, but systems that are not designed to detect and correct it deterministically. FluxCD addresses this by making drift, failure, and recovery explicit, first-class behaviors of the platform.
FluxCD reframes drift in three ways:
- Reconciliation event
Any divergence between Git and the cluster state triggers the reconciliation loop automatically, without waiting for human intervention. - Policy violation
Git is enforced as the single source of truth. Changes made outside Git are treated as non-compliant and corrected accordingly. - Recoverable state
The system is always one successful sync away from a healthy state, making recovery deterministic and repeatable.
Within this model, HelmRelease health checks convert runtime signals into automated remediation. Readiness failures and timeouts drive retries or rollbacks, turning alerts into self-healing actions.
The outcome is a shift from reactive operations to designed resilience, where failure is expected, recovery is automated, and stability is maintained through continuous reconciliation.
Governance as a Continuous, Automated Process
FluxCD enables robust, asynchronous governance without creating centralized bottlenecks.
- Declarative Guardrails: Policies are codified in
HelmReleasespecs and validated through Git pull requests, replacing manual checklists. - Git as the System of Record: Every change is a peer-reviewed PR, providing a complete, immutable audit trail for compliance. This is the “Audit Trail” for production changes.
- Automated Enforcement: The cluster self-heals from configuration drift, enforcing policy continuously.
- Real-Time Observability: Flux’s
notification-controllerintegrates with tools like Slack or MS Teams, providing instant alerts on reconciliation success, failure, or drift detection.
This model eliminates runtime ticketing for configuration changes and manual approval gates in production. Compliance becomes continuous and auditable by default.
When FluxCD + Helm Is the Right Choice (And When It Isn’t)
1. The “Green Zone”: High-Scale Enterprises
FluxCD + Helm is a strong fit when change volume, team count, and compliance pressure demand deterministic control.
- Multi-tenancy: Flux enables namespace - and team-level isolation while enforcing shared platform contracts across dozens of teams.
- Global distribution: Declarative reconciliation allows consistent state synchronization across 10+ clusters without multiplying pipelines.
- Compliance and auditability: Git becomes the immutable audit trail - every production change is traceable, reviewable, and reversible.
In these environments, the operational overhead of FluxCD is offset by reduced incident rates and predictable change management.
2. The “Yellow Zone”: Mid-Market and Growing Startups
For organizations transitioning from ad-hoc operations to structured delivery, FluxCD represents a strategic investment.
- Primary value: Replacing manual fixes and environment-specific hacks with systemic, policy-driven discipline.
- Trade-off: Teams must accept a steeper learning curve and upfront design effort in exchange for long-term stability and scalability.
Here, FluxCD often acts as a forcing function for better engineering practices.
3. The “Red Zone”: When to Avoid
FluxCD is a poor fit when foundational practices are missing.
- High operational tax: If maintaining reconciliation logic costs more effort than the deployments themselves, the model is premature.
- Weak Git discipline: Teams that rely on manual cluster edits or lack structured version control will struggle - Flux assumes Git is authoritative.
Common Anti-Patterns Leaders Should Watch For
- The “Push” Mindset: Treating Flux like a CI pipeline and expecting immediate, linear execution rather than understanding its continuous reconciliation loop.
- The “God Chart”: Creating a single, monolithic Helm chart attempting to configure everything, which becomes unmaintainable.
- “Shadow IT” Hotfixes: Engineers using
kubectl editto bypass Git, creating drift that Flux will faithfully - and correctly - overwrite, confusing. - Misaligned Metrics: Celebrating commit frequency over cluster state health and consistency.
Strategic Takeaway: FluxCD + Helm as a Production Control System
FluxCD with Helm is not about deploying faster - it is about preventing value erosion in production. Its real strength lies in turning deployment from a one-time event into a continuous guarantee of system correctness.
By combining declarative Helm releases with continuous reconciliation, production is constantly verified against declared intent, not assumed to be stable after rollout.
For leadership, the outcome is clear and measurable:
- Fewer incidents, as drift and misconfigurations are corrected automatically
- Faster recovery, through deterministic, machine-led remediation
- Lower operational risk per release, because every change is governed by enforced policies
At scale, reliability is achieved not by slowing teams down, but by systems designed to protect production continuously. FluxCD + Helm functions as the production control system.
Final Takeaway
FluxCD with Helm serves as a specialized controller for maintaining the desired state, transforming deployments into a continuous guarantee of system integrity. By moving away from discrete, manual events, organizations can realize several measurable operational benefits:
- Improved MTTR via Automated Remediation: Flux reduces Mean Time to Recovery by detecting failures during the reconciliation interval (typically 1–5 minutes). Through the HelmRelease CRD, Flux can trigger automated rollbacks if Helm tests fail or upgrades stall.
- Continuous Auditability: Leveraging Git as the single source of truth provides an immutable audit trail, simplifying compliance and root cause analysis (RCA) as documented in the Flux GitOps Toolkit.
- Drift Detection & Stability: The helm-controller proactively identifies and corrects configuration drift. This ensures the cluster remains synchronized with the Git-defined state, mitigating the risks associated with manual “hotfixes.”
By adopting this model, as Improwised does with its modern toolstack, you shift from high-risk deployments to a resilient, self-healing infrastructure. The deployment process becomes a predictable foundation for scaling business value rather than a source of operational instability.
Frequently Asked Question
Get quick answers to common queries. Explore our FAQs for helpful insights and solutions.
Written by
Chintan Viradiya
Chintan Viradiya is a DevOps Engineer at Improwised Technologies. Passionate about Infrastructure as Code and CI/CD pipelines, he focuses on optimizing cloud deployments and enhancing the security and performance of modern applications. He plays a key role in ensuring high availability and driving DevOps best practices across projects

February 12, 2026
DevSecOps Architecture Explained: Security as Code, Policy Automation, and GitOps
Chintan Viradiya
Author


January 19, 2026
Site Reliability Engineering in Practice: Building Reliable Systems at Scale
Annavar Satish
Author



January 2, 2026
Day-2 Operations: Building Reliable, Scalable, and Operable Production Systems
Shyam Kapdi
Author
Optimize Your Cloud. Cut Costs. Accelerate Performance.
Struggling with slow deployments and rising cloud costs?
Our tailored platform engineering solutions enhance efficiency, boost speed, and reduce expenses.