April 30, 2026
Cloud Cost Optimization: Why Architecture Matters

Chandan Teekinavar
Author

Shyam Kapdi
Contributor

Shailesh Davara
Reviewer
Every quarter, engineering teams run through the same routine. They right-size instances, shut down idle environments, clean up orphaned resources, and cut the cloud bill by 15-20%. Then, six months later, the bill is back where it started, or higher.
This is not a spending discipline problem. It is not a tooling problem. It is an architecture problem.
The way your systems are designed, and the decisions made two or three years ago,o are continuously generating costs. And no FinOps dashboard will show you that.
1. Why Right-Sizing Doesn’t Stick
There are two types of cloud waste. Most teams only ever fix one of them.
Operational waste is visible. Idle VMs, oversized databases, forgotten load balancers. FinOps tools catch this well. You prune it, costs drop, and everyone feels good.
Architectural waste is invisible. It comes from how your system is built. Things like:
-
A monolith that scales the entire application when only one function needs more capacity
-
Synchronous service calls that keep connections open longer than needed
-
Data pipelines that move full datasets when only deltas are required
-
Logging and observability setups that write ten times more data than anyone ever reads
These patterns don’t show up as line items. They show up as ‘expected’ costs that grow in proportion to your usage, even when they don’t need to.
Right-sizing helps for a while. But if the architecture keeps regenerating waste, trimming the edges is like bailing water from a leaking boat.
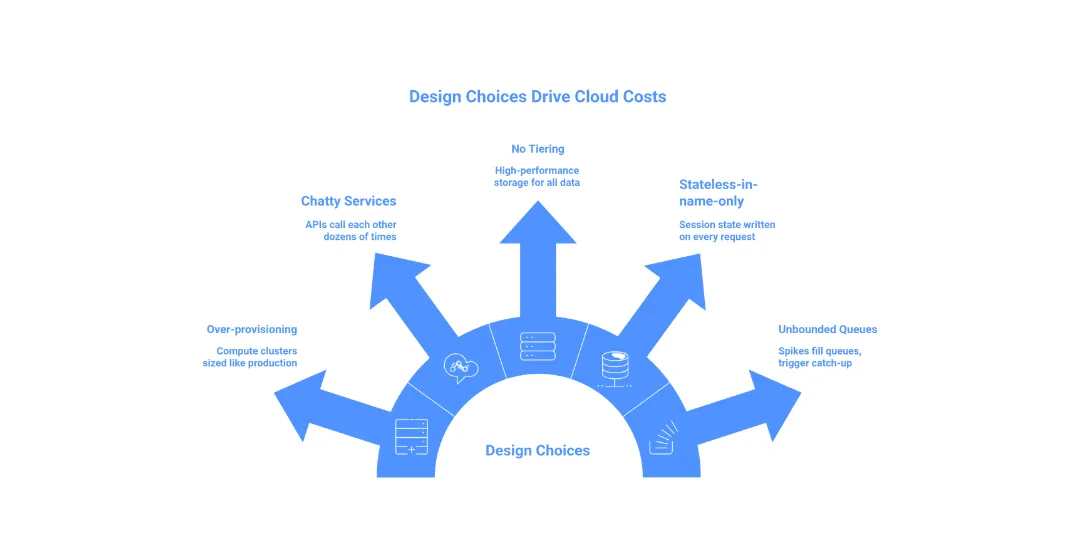
2. The Five Structural Cost Anchors FinOps Tools Miss
Here are five architectural patterns that reliably drive cloud cost up, none of which appear clearly in standard cost reports:
-
Over-provisioned compute across environments, staging and dev clusters sized like production, running 24/7.
-
Chatty service communication, internal APIs calling each other dozens of times per user request, often across availability zones.
-
No data tiering, everything is stored in the same high-performance tier regardless of access frequency.
-
Stateless-in-name-only services, applications that claim to be stateless but write session state to shared databases on every request.
-
Unbounded async queues, event-driven systems with no back-pressure, where a single spike fills queues and triggers expensive catch-up compute.
Each of these is a design choice. Each of them has a real dollar cost. And each of them looks, in a cost dashboard, like normal infrastructure spend.
3. How Architecture Decisions Made Two Years Ago Are Generating Cost Today
When a system is designed, cost is rarely the primary concern. Speed to market, team autonomy, and fault tolerance take priority. That’s reasonable.
But the consequences show up later:
-
A team picked a managed service for convenience, but it costs 4x more at scale than a self-managed alternative
-
Services were built with fine-grained APIs to enable flexibility, but now they generate enormous inter-service traffic costs.
-
The data model was designed for writes, not reads. Now, every read query scans more data than necessary.
None of these decisions was wrong at the time. The problem is that they were never revisited. As your tech infrastructure scales, usage grows, and the cost model embedded in the architecture scales right along with it.
By the time the bill is noticeable, the architecture is load-bearing. Changing it requires engineering time, testing, and migration risk, which is exactly why it doesn’t happen during quarterly cost sprints.
4. What a Real Architectural Cost Audit Looks Like
An architectural cost audit is not a cloud cost review. It is a structured engineering review with cost as a first-class input.
It covers:
-
Service topology: How services communicate, how often, and what it costs per million requests
-
Data flow mapping: Where data is written, stored, moved, and transformed, and what the cost profile of each step is
-
Compute scaling behavior: Does compute scale with actual load, or with system-wide assumptions that haven’t been tested in years?
-
Storage tiering is data placed in the right storage class for its actual access pattern
-
Build and deployment costs: How much CI/CD infrastructure runs, how often, and how much of it is idle.
Who should own this?
Not the FinOps team. Not finance. This requires your senior platform engineers and architects, the people who understand why the system was built the way it was and what it would take to change.
It should run as a structured review, not a one-off project. Quarterly is realistic. The output should be a prioritized list of architectural changes with cost and performance impact estimates, not a report that gets filed and forgotten.
5. Building Cost-Awareness Into Platform Design Before the Next Spike
The real fix is upstream. Cost needs to be part of how platform decisions are made, before systems are built, not after bills arrive.
A few things that actually work:
-
Cost estimates in design reviews: When a new service or feature is being designed, a rough cost model is required as part of the design doc
-
Per-service cost attribution not just totals by team, but costs are mapped to specific services, so engineers can see the direct impact of their systems
-
Open-source-first defaults managed services are fine, but when the cost gap is significant at scale, the default should be to consider open-source alternatives on your own infrastructure
-
Architecture fitness functions automated checks that flag when a service’s cost per unit of work crosses a defined threshold
None of this requires a new platform or a new tool. It requires adding cost as a dimension to the engineering conversations that are already happening.
Conclusion
Cloud cost reduction initiatives fail to stick because they treat the symptom of spend without addressing the cause of the architecture.
Every engineering organization eventually figures this out. The ones that figure it out earlier stop running the same cost sprint every six months and start building systems that don’t continuously regenerate the waste they just cleaned up.
The bill is a signal. The architecture is the problem.
Stop running the same cost sprint every six months. Contact Improwised today to schedule a comprehensive architecture review and build systems that scale efficiently.
Frequently Asked Question
Get quick answers to common queries. Explore our FAQs for helpful insights and solutions.
Cloud costs rise again because most optimizations target visible operational waste, while underlying architectural patterns continue to generate new costs over time.
Operational waste includes idle or oversized resources that can be removed directly, while architectural waste comes from system design choices that continuously generate cost as usage grows.
Right-sizing reduces excess capacity temporarily, but if system design causes inefficient scaling or unnecessary work, costs return as load increases.
Common patterns include over-provisioned environments, excessive inter-service communication, lack of data tiering, unnecessary state management, and unbounded event processing systems.
These costs appear as normal usage because they are built into system behavior, not isolated as anomalies or unused resources.
Decisions made for speed or flexibility often scale inefficiently over time, increasing compute, storage, and network costs as usage grows.
An architectural cost audit is a structured engineering review that analyzes service communication, data flow, scaling behavior, and storage usage to identify cost drivers in system design.
Written by
Chandan Teekinavar
Chandan Teekinavar is a DevOps Engineer at Improwised Technologies. Passionate about Infrastructure as Code and CI/CD pipelines, he focuses on optimizing cloud deployments and enhancing the security and performance of modern applications. He plays a key role in ensuring high availability and driving DevOps best practices across projects


June 25, 2026
Why Platform Teams Produce Gatekeepers Instead of Partners
Hussain Gandhi
Author



June 23, 2026
CI/CD, DevOps, or Platform Engineering, Which One Does Your Team Actually Need?
Divya Kathiriya
Author



June 18, 2026
The Real Cost of Tribal Knowledge: How to Audit and Eliminate Operational Risk
Chandan Teekinavar
Author
Optimize Your Cloud. Cut Costs. Accelerate Performance.
Struggling with slow deployments and rising cloud costs?
Our tailored platform engineering solutions enhance efficiency, boost speed, and reduce expenses.