June 10, 2026
AI Hallucination in Production: What Your Monitoring Tools Are Missing

Hussain Gandhi
Author

Shyam Kapdi
Contributor

Shailesh Davara
Reviewer
I have spent the better part of 15+ years making sure systems do not fall over, including building the underlying architecture for a leading AI Orchestration Platform. Databases crash and throw error codes. Servers go down, and pages fire. Networks fail, and dashboards go red. We built entire cultures around catching failures fast.
None of that training prepared me for what AI does when it fails.
When an AI fails, your monitoring dashboard stays green. CPU looks normal. Memory looks normal. Response times look normal. Meanwhile, the AI just told your customer the wrong price, your insurance chatbot gave legal advice it is not qualified to give, or your sales assistant made a promise your company cannot keep.
In perfect grammar. With full confidence. Zero error codes.
Why AI Output Monitoring Is Different From Everything You Have Done Before
Think about how we monitor traditional applications. We watch metrics. We set thresholds. If a value goes outside the acceptable range, we get an alert.
That model assumes the problem is measurable with numbers. Is the CPU above 80%? Is the memory over threshold? Is the response time beyond the SLA?
AI failures are not numerical. They are semantic. The AI gave a wrong answer, and wrong answers do not show up in any metric your ops team is watching today.
The result is a blind spot that most organizations do not even know they have. You find out about it in three ways: a customer complaint, a legal notice, or a screenshot on social media. None of those is a good way to find out.
The Real Risk Is Not That AI Will Break. It Is That AI Will Be Wrong Quietly.
I have watched companies deploy AI and immediately start checking the wrong things. They watch for downtime. They watch for latency. They set up error rate dashboards.
Those things matter, but they are not where the damage happens with AI.
The damage happens when the AI is technically working fine, it is up, it is fast, it is responding, but what it is saying is wrong. It invented a product feature that does not exist. It quoted a price from six months ago. It recommended something that creates a liability. It told a user in one country something that is regulated differently in their region.
These are not edge cases. This is the normal failure mode of AI systems in production. And right now, most organizations have no systematic way to catch it before the customer does. When we build Autonomous AI Agents for our clients, structuring these semantic guardrails is step one, not an afterthought.
| Ask yourself this right now: Do you know what your AI said to your users today? Not last week. Not in the last bug report. Today. And while you are checking your outputs, you should also be checking your costs. Read our guide on how to stop burning cash on AI tokens to ensure your models aren’t quietly inflating your cloud bill, either. |
|---|
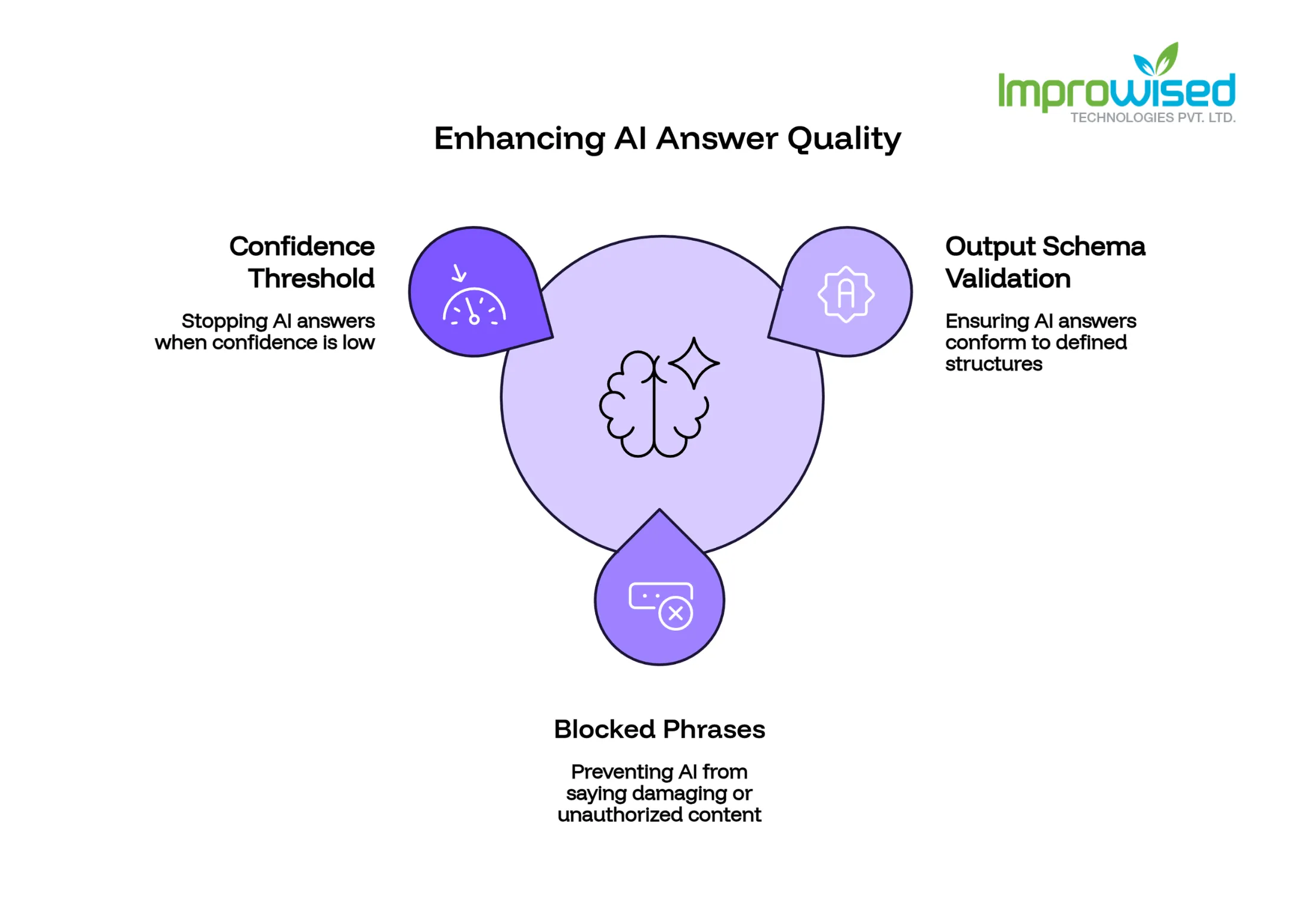
Three Things You Can Put in Place This Week
I want to be direct here: this is not a multi-quarter project. The basic version of this does not require new infrastructure, new vendors, or a model rebuild. Most teams can put the foundation in place in a single sprint. Here is what that looks like.
Step 1: Define What a Legal Answer Looks Like
Every AI output in your product should conform to a defined structure. What type of answer is acceptable? What length? What values are allowed and which are not?
This is output schema validation. You are essentially drawing a fence around what the AI is allowed to say. Anything outside the fence gets stopped before it reaches the user. This alone catches a large category of AI hallucinations, the ones where the model makes up a number, a date, a product name, or a specification that simply does not match what your system is supposed to deliver.
Think of it the way you think of input validation on a web form. You would not let a user type letters into a field that expects a phone number. The same logic applies to what your AI sends out.
Step 2: Maintain a Short List of Things the AI Must Never Say
Every organization has a handful of things that would be genuinely damaging if an AI said them. Competitor names in a sales context. Specific legal language your company is not authorized to use. Pricing that is out of date or market-specific. Regulatory statements that vary by geography.
Write those down. Maintain a list. Run every AI output through a check before it reaches the user. If any blocked phrase appears, stop the output and return a fallback message instead.
This check runs in milliseconds. It adds no meaningful latency to your system. It is one of the highest-value-per-hour things a team can build when it comes to AI risk management.
Step 3: Stop the AI When It Is Guessing
AI models produce answers even when they are not sure. They do not stop and say, “I do not know.” They guess, and they often guess with the same confident tone they use when they do know.
Most models expose an internal confidence measure. When that score falls below a threshold you define, do not let the answer go to the user. Route it to a human instead, or return a message that says the system cannot answer this question right now and directs the user to contact support.
A user who gets a “we are not sure, here is how to get help” message is mildly inconvenienced. A user who gets a wrong answer delivered with confidence is a potential chargeback, a support ticket, a legal complaint, or a social media post. The math is not complicated.
The 3-Rule Guardrail Checklist
Screenshot this. Put it on your next engineering review agenda.
| WHAT TO DO | WHY IT MATTERS |
|---|---|
| Define what a legal AI output looks like — and reject everything else before it reaches the user | Stops hallucinations that produce structurally wrong answers — wrong type, wrong format, made-up values |
| Keep a short blocklist of things the AI must never produce — competitor names, unauthorized legal language, out-of-date pricing | Runs in milliseconds. Protects against the specific, high-damage outputs that show up in legal complaints and compliance reviews |
| Set a confidence floor — when the model is below threshold, route to a human or a safe fallback, not to the user | Catches the guesses before they become customer complaints. The model does not know it is guessing — but you can catch it before the user does |
One Afternoon vs. One Breach
Here is a comparison I keep coming back to when teams hesitate on this.
| PUTTING GUARDRAILS IN PLACE | DEALING WITH AN AI-CAUSED INCIDENT |
|---|---|
| One sprint of engineering time | Customer complaint and support cost |
| No new infrastructure | Possible legal or compliance exposure |
| No model retraining | Reputational damage that is hard to quantify |
| Thin middleware layer, done in days | Emergency engineering work under pressure |
The teams that get this wrong are not being careless. They are using the evaluation framework that worked for every other system they have ever run. The problem is that the framework was built for a different kind of failure. If you aren’t sure if your current framework is ready for AI workloads, take our free Platform Engineering Maturity Assessment to find your blind spots.
Run This Audit on Your Own System Today
Before you bring in any tooling or external help, start with this. Ask your AI system the following questions and watch what it does:
| What does your AI say when it does not know the answer? Ask it something genuinely outside its scope or your product’s domain. Does it say it does not know? Or does it construct a confident-sounding answer? Ask a question that has a clear wrong answer. Does it catch itself? Or does it answer smoothly and incorrectly? Ask it something that requires current information it should not have. Does it acknowledge the gap? Or does it fill it in? |
|---|
If it answers confidently in all three cases, you have a gap. The AI is not lying to you; it is doing exactly what it was built to do… That is your job. You have to build the system that stops it. (Not sure where your blind spots are? Our Infrastructure and Architecture Review maps these exact vulnerabilities before they reach production. It generates the most likely next answer. It does not stop and say, “I am not sure.” That is your job. You have to build the system that stops it.
Where to Go From Here
If you run that audit and the answers concern you, the path forward is not complicated. The three steps described here are output validation, a phrase blocklist, and a confidence floor from the basic layer. They sit between your AI model and your front end. They require no changes to the model. They require no new infrastructure.
Most engineering teams can have the basic version running within a week. The gaps you find when you test it will tell you what to prioritize next.
The harder part is deciding that this is worth doing before something goes wrong. Every team I have talked to that skipped this step eventually wished they had not. None of the teams that built it first has told me they regret the sprint.
| If you do not know what your AI said to your users today, you are carrying unmeasured risk. Not theoretical risk. Not future risk. Risk that is active right now, in every conversation your AI is having with your customers, with no dashboard showing you what is happening. |
|---|
We can help you stand up a basic guardrail layer this week. No new infrastructure required. Contact us today, let us look at what you currently have, and show you exactly where your semantic gaps are before your customers find them.
Frequently Asked Question
Get quick answers to common queries. Explore our FAQs for helpful insights and solutions.
Traditional monitoring tools are built to track numerical metrics like CPU usage, latency, and API uptime. AI failures, however, are semantic. An AI model can show 99.9% uptime and zero error codes on your dashboard while confidently generating false pricing, incorrect legal advice, or non-existent product features to your customers.
The biggest risk is not system downtime; it is that the AI will fail quietly. Models do not naturally stop and say, 'I don't know.' Instead, they guess. They will provide grammatically perfect, highly confident, but factually incorrect answers that expose your company to compliance risks, legal liabilities, and reputational damage without ever triggering an operational alert.
You must implement a strict confidence floor. Most AI models expose an internal confidence score for their outputs. When that score drops below a pre-defined threshold, your system must intercept the response. Instead of letting the AI guess, the system should automatically route the query to a human support agent or return a safe fallback message.
Output schema validation acts as a structural fence around what your AI is legally allowed to generate. By explicitly defining the acceptable format, length, and data types of a response (similar to web form input validation), you can automatically intercept and reject structural hallucinations like made-up dates or impossible product specifications before they reach the end user.
You do not need to rebuild your infrastructure or retrain models to stop hallucinations. In a single sprint, you can deploy a thin middleware guardrail layer that performs three millisecond-speed checks: enforcing output schema validation, filtering responses through a strict blocklist of forbidden terms (like competitor names or unauthorized legal phrases), and applying a confidence threshold.
Written by
Hussain Gandhi
Hussain Gandhi is a DevOps Engineer at Improwised Technologies Pvt Ltd. He focuses on building scalable systems through automation and scripting. He has hands-on experience with cloud infrastructure, CI/CD pipelines, and infrastructure as code. Hussain combines strong technical skills with a collaborative work style. In his free time, he enjoys learning new things.
July 16, 2026
What a DevSecOps Architecture Actually Looks Like (Not the Diagram, the Real Thing)
Hussain Gandhi
Author


July 6, 2026
Migration Debt: Why Unfinished Migrations Are Your Most Expensive Technical Debt
Chandan Teekinavar
Author



June 30, 2026
Your AI Bill Is Going Up. Your Output Isn't. Here's Why.
Chintan Viradiya
Author

Optimize Your Cloud. Cut Costs. Accelerate Performance.
Struggling with slow deployments and rising cloud costs?
Our platform engineering solutions are built on open-source tools and use AI natively across the workflow.