June 30, 2026
Your AI Bill Is Going Up. Your Output Isn't. Here's Why.

Chintan Viradiya
Author

Shyam Kapdi
Contributor

Shailesh Davara
Reviewer
Token prices dropped 67% year-over-year. You’d expect your AI bill to drop with it.
Instead, 73% of enterprises say AI costs went over budget in 2026.
I’ve been running cloud infrastructure and platform engineering operations for over 15+ years. I’ve watched teams overbuy compute, over-provision storage, and misread cloud invoices at scale. This feels the same except it’s moving faster, and fewer people in the room know how to read the bill.
This isn’t an AI problem. It’s a cost governance problem. And it has a fix.
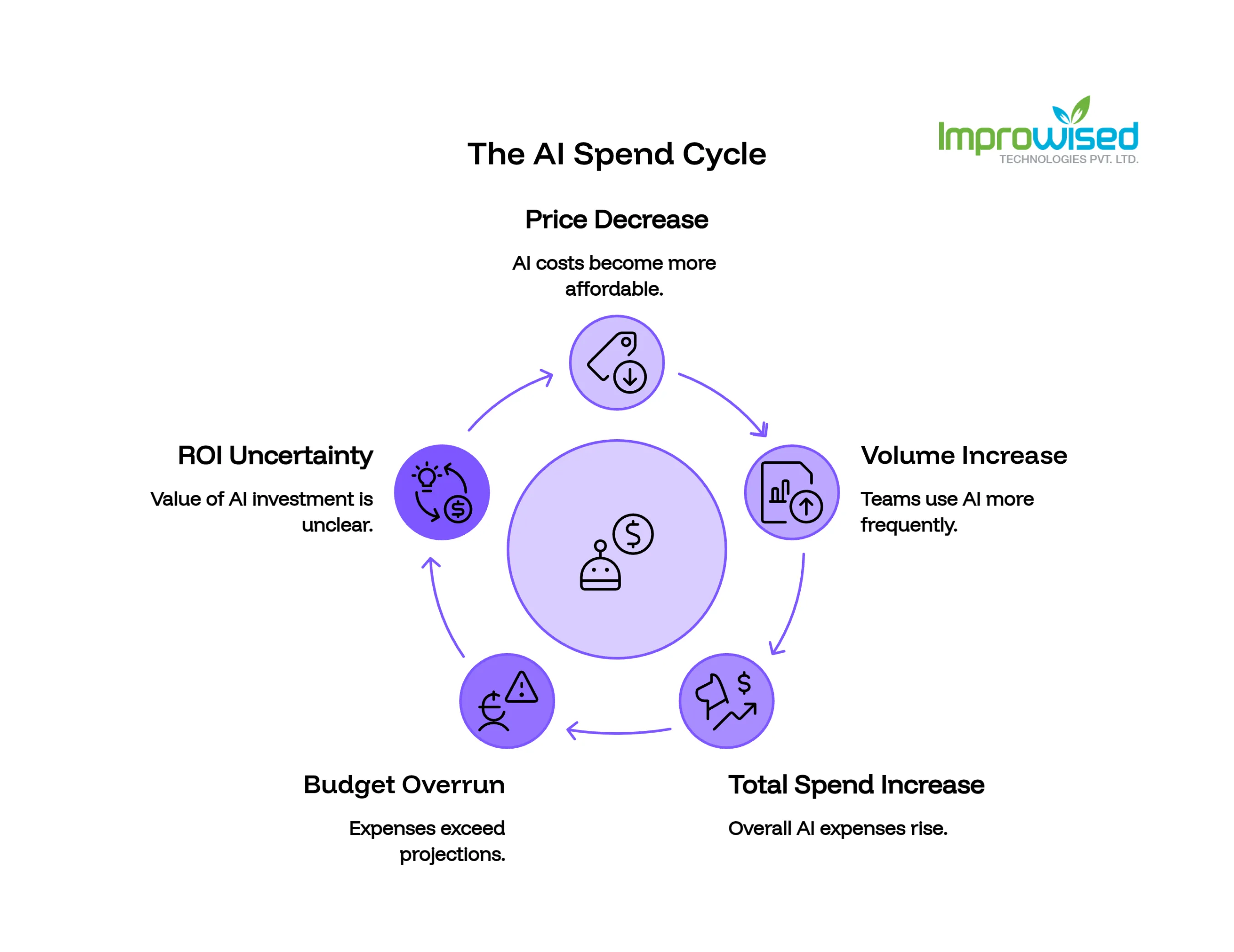
What’s Actually Happening With Your AI Spend
Here’s the math that breaks most budgets:
Price goes down → volume explodes → total spend goes up.
When something gets cheaper, teams use more of it. That’s rational. But nobody updated the budget model to account for 10x the volume at 67% less per unit. The result: the bill is higher than anyone projected, and nobody has a clear answer for what the company got in return.
Uber had 84% of its developers actively using AI coding agents by March 2026. The full-year AI budget was gone by April. Not because the tools stopped working, but because nobody set a ceiling on how much each workflow was allowed to spend before it ran.
Meta had a different version of the same problem. Employees were inflating AI usage metrics, which they internally called “tokenmaxxing,” to look productive, without a matching increase in actual output. Uber’s own COO said the link between token spend and measurable output “is not there yet.”
These aren’t small companies figuring out AI for the first time. These are organizations with large engineering teams, experienced leadership, and real money on the table. If they hit this wall, your team will too, or already has.
What a Token Actually Is
Think of tokens like electricity units on your utility bill.
Every word you send to an AI model costs tokens. Every word it sends back costs tokens. You don’t see the meter ticking, but it’s ticking constantly.
To put it in real numbers:
- A short prompt = roughly 50 tokens
- A full document analysis = 50,000+ tokens
- An AI agent completing a 20-step workflow = each step is its own separate charge
That last one is where most teams get surprised. You approved a task. The agent decided how many steps to take, how much context to carry, and how many calls to make. You approved the outcome, but the agent ran the meter.
Where the Money Actually Goes (That Nobody Tracks)
Most AI overspending comes from four places. None of them are dramatic. All of them are fixable.
1. Defaulting to the most expensive model for everything
There’s a 20–50x price gap between top-tier models (GPT-4, Claude Opus) and smaller, task-specific models. Teams default to the expensive one because it feels safer, not because the task requires it. Classifying a support ticket doesn’t need the same model that writes a legal brief. Using GPT-4 for everything is like hiring a senior architect to sort your filing cabinet.
2. Agents running in loops with no cost ceiling
AI agents are designed to keep working until they finish—or until you stop them. If you deploy an agent to production without a per-run token budget, it will run until the task is “done” by its own definition. Nobody set a ceiling. Nobody gets an alert. The bill arrives at the end of the month.
3. Long context windows passed by default
Most AI frameworks pass the entire conversation history or the full document to the model by default even when the model only needs the last two paragraphs. That full context costs tokens every single call. Multiply that by thousands of daily requests, and you’re paying to resend information the model already processed.
4. Zero visibility across models and teams
The average enterprise engineering org now runs 16+ AI models across different teams and tools. There is rarely a single view of what’s being spent where. Nobody is tagging token spend by team, by workflow, or by business outcome. Finance sees one number at the end of the month. Engineering doesn’t know which tool drove it. This lack of observability is a massive leading indicator of risk, much like how hidden system flaws ultimately trigger production incidents that expose low system maturity.
The Uber and Meta Numbers, Plain and Simple
Uber:
- 84% developer AI adoption by March 2026
- Full-year AI coding budget depleted by April 2026
- 4 months into a 12-month budget cycle
Meta:
- Internal term “tokenmaxxing” — employees increasing AI usage to inflate productivity metrics
- No matching increase in actual shipped work
- Memo culture around AI spend, not measurement culture
What both cases share: Neither company had a system that connected token consumption to a business result. Volume was tracked. Value wasn’t.
That’s the actual problem.
What to Do About It?
You don’t need a new platform to fix this. You need four decisions. Though if your current setup is a complete black box, an external Infrastructure and Architecture Review can map your cost leaks quickly.
Route tasks to the right model, not the default one
- Simple classification, tagging, and summarization tasks → Llama 3 8B or similar open-source models handle these well and cost a fraction of the price
- Complex reasoning, multi-step generation → use the expensive model only here
- This one change alone can cut 40–60% of spend in most orgs
Turn on prompt caching
If your system prompt is the same across requests, which it usually is, you’re paying to resend it every single time. Prompt caching stores the repeated portion and reuses it. Savings: up to 90% on cached tokens. This is already available in most major model APIs. Most teams haven’t turned it on because nobody told them to look.
Set per-workflow cost ceilings before going to production
Before you deploy any AI agent or workflow, define a token budget for it. If a task costs more than X tokens, it stops and flags for review. This is the same thing you do with cloud auto-scaling limits. It should be standard practice here too.
Tag and track token spend like cloud spend
- Assign token costs to teams, workflows, and business outcomes
- Report it monthly the same way you report compute and storage
- Make it visible to the people running the workflows, not just the people paying the invoice
- See how we built transparent, multi-cloud cost visibility in our Cloud-Native Managed Platform Case Study
None of this requires a new vendor. It requires a decision that AI spend gets managed the same way every other infrastructure cost gets managed.
The Number That Actually Matters
Most teams measure AI adoption by tokens per developer. That’s the wrong metric.
The right metric is cost per hour saved or, more simply: what did we get for this spend?
If a developer saves 2 hours a week using AI, and those 2 hours go toward work that ships product faster, that has a dollar value. If they spend 2 hours a week prompting an agent that loops without producing anything useful, that also has a dollar value—and it’s negative.
Ask your team this question: “What is our monthly AI API spend per developer, and what output can we directly connect to it?”
If you don’t know the spend number, that’s the first thing to fix.
If you know the spend but can’t connect it to output, that’s the second thing.
Benchmark your current cost governance and observability against industry standards using our free Platform Engineering Maturity Assessment.
The technology isn’t the problem. The measurement is. Contact our team today to set up a cost governance architecture that ensures your AI budget actually drives engineering velocity.
Frequently Asked Question
Get quick answers to common queries. Explore our FAQs for helpful insights and solutions.
Token prices dropped, but usage exploded. Most companies are processing 5–10x as many AI requests as they did a year ago. A lower price per token doesn't matter if volume multiplies faster than the discount. The net result is a higher total bill even though each token costs less. This is the same pattern that happened with cloud storage- as it got cheaper, teams stored more until the bill was bigger than before.
Tokenmaxxing is when employees inflate AI usage to look productive without actually shipping more work. Meta used this term internally. It matters because it means your AI spend metric is decoupled from your output metric. If the organization rewards high AI usage without measuring results, teams will optimize for usage, not value. You end up paying more and getting the same amount of work done.
The metric that matters is cost per hour saved, not tokens per developer. Calculate it like this: (hours saved per developer per week × hourly cost) ÷ monthly AI spend per developer. If the ratio is greater than 1, you're getting positive return. If you can't connect spend to saved hours or shipped output, you don't have an ROI measurement; you have an activity measurement. Those are not the same thing.
Set a token budget ceiling for every workflow before it goes to production. Decide: 'This task is allowed to use X tokens maximum. If it exceeds that, it stops and flags for review.' This is the same logic as cloud auto-scaling limits or spend alerts. Without it, agents will run as long as the task requires, and the task definition is the agent's, not yours. Per-workflow budgets are the single highest-impact change most teams can make immediately.
The average enterprise engineering team now runs 16+ AI models across tools and teams. The problem isn't the number; it's that there's rarely consolidated visibility across all of them. Each team sees their own tool's usage. Nobody sees the full picture. Finance sees one aggregated number at month-end. Without tagging token spend by team, workflow, and business outcome, you can't identify where waste is happening or which workflows are actually delivering value.
Written by
Chintan Viradiya
Chintan Viradiya is a DevOps Engineer at Improwised Technologies. Passionate about Infrastructure as Code and CI/CD pipelines, he focuses on optimizing cloud deployments and enhancing the security and performance of modern applications. He plays a key role in ensuring high availability and driving DevOps best practices across projects


June 25, 2026
Why Platform Teams Produce Gatekeepers Instead of Partners
Hussain Gandhi
Author



June 23, 2026
CI/CD, DevOps, or Platform Engineering, Which One Does Your Team Actually Need?
Divya Kathiriya
Author



June 18, 2026
The Real Cost of Tribal Knowledge: How to Audit and Eliminate Operational Risk
Chandan Teekinavar
Author

Optimize Your Cloud. Cut Costs. Accelerate Performance.
Struggling with slow deployments and rising cloud costs?
Our tailored platform engineering solutions enhance efficiency, boost speed, and reduce expenses.