June 25, 2026
Why Platform Teams Produce Gatekeepers Instead of Partners

Hussain Gandhi
Author

Shyam Kapdi
Contributor

Shailesh Davara
Reviewer
You invest heavily in a platform team. They build good things: standardized pipelines, security guardrails, and deployment tooling. Then, a year later, you notice developers are spinning up their own tools, running their own scripts in production, bypassing the platform entirely.
That’s not a people problem. That’s an incentives problem.
Here’s what’s actually happening.
Why Platform Teams Are Built to Say No (Even When They Don’t Mean To)
Platform teams are almost always measured on things like uptime, incident count, and compliance. Those are the right things to care about from a stability standpoint. But here’s the unintended consequence: when your success metrics are about control and stability, the safest thing you can do is slow things down and add approval steps.
That’s not a character flaw. It’s a rational response to how the team is being evaluated.
If a platform engineer approves a request quickly and something breaks, that’s on them. If they slow it down, ask for more documentation, and add a review step, they’re covered. The incentive structure quietly rewards friction.
Over time, the platform team stops feeling like a tool that helps engineers move faster. It starts feeling like a gate they have to get through.
The developers building features feel this every day. They submit a request and wait. They ask why a certain tool isn’t supported and get a 10-day ticket response. They want to use a service the platform doesn’t cover, so they build their own.
Nobody planned for this outcome. But it’s almost guaranteed when platform teams are measured on the wrong things.
How Shadow IT Actually Gets Created - Step by Step
Shadow IT in engineering organizations doesn’t come from reckless developers ignoring the rules. It comes from friction that accumulates over time.
Here’s how the sequence usually goes:
A developer needs to deploy a service. The platform team’s standard process takes 2 weeks and requires three approvals. The product deadline is in 10 days. So the developer spins up their own environment, uses a personal cloud account or a team credit card, and gets the job done.
That “temporary” setup doesn’t get torn down. It becomes permanent.
Three months later, a critical fix for a customer is running on infrastructure that wasn’t built to production standards, isn’t monitored properly, and that the platform team doesn’t know exists. This is precisely how forgotten shadow IT turns into the kind of production incidents that expose low system maturity.
Six months later, there are 12 of those environments. Nobody has a full list. Nobody knows what’s connected to what.
Now you have a security and reliability problem that’s significantly harder to clean up than the original friction problem would have been to fix.
This pattern is especially common in companies that have invested the most in platform tooling. The investment creates a false sense of coverage. Leaders assume developers are using the platform. The developers have quietly moved around it.
The ‘Platform as a Product’ Idea Breaks Down Without the Right Customer Mindset
A lot of engineering organizations have adopted the idea of “platform as a product,” meaning the platform team should treat internal developers like customers. It’s a good concept. Most implementations of it fail.
Here’s why: you can call your internal developers “customers,” but if the platform team’s budget, performance reviews, and goals aren’t tied to developer satisfaction and adoption, nothing changes. The language changes. The behavior doesn’t.
A real product team is measured on whether customers use the product and whether those customers achieve what they came to do. When we deliver Platform Engineering Services to a client, voluntary developer adoption is our primary success metric, not just whether the Kubernetes cluster is turned on. A platform team measured only on uptime and security compliance is not operating like a product team, regardless of what the org chart says.
The other failure mode is treating all developers the same. A senior engineer deploying a high-traffic microservice has different needs than a data scientist spinning up a batch job. A platform built to one standard for both ends up serving neither well.
When developers feel like the platform wasn’t built for them, when it’s clearly more about what’s convenient for the platform team to support than what’s useful for the people building products, they stop using it. They don’t file complaints. They just find another way.
The Metrics That Actually Drive Platform Adoption
I’ve seen companies try to fix this by adding a developer satisfaction survey and calling it a day. That’s a start, but it’s not enough.
The metrics that actually move platform adoption are:
Time to first deployment. How long does it take a new developer to go from nothing to running something in production using the platform? If that number is more than a day, you have a problem. This single metric captures onboarding friction better than any survey.
Self-service completion rate. What percentage of developers who start a platform workflow complete it without opening a support ticket or asking someone for help? If the answer is below 70%, the platform is too complicated.
Platform coverage vs. actual production services. What percentage of services running in production are actually on the platform? If this number is below 90%, you have shadow IT. Track it, report it to leadership quarterly.
Repeat usage rate. If a developer uses the platform once and doesn’t come back, that’s a signal. Platforms that work get used repeatedly. Track whether developers who used the platform 90 days ago are still using it today.
Ticket deflection. How many platform-related support requests are being resolved without the platform team being involved? High self-service deflection means the platform is actually self-serviceable.
These metrics force a different conversation. Instead of “are we stable,” the question becomes “are we useful?” Both matter. But only one of them has been consistently measured in most organizations.
How to Reset Platform Team Goals Without Dropping Reliability
This is where most leaders hesitate. They’re worried that if you shift the platform team’s focus toward adoption and developer experience, reliability will suffer.
That concern is understandable, but it’s based on a false trade-off.
Reliability and adoption aren’t opposites. The platform that developers actually use is more secure and more reliable than the shadow infrastructure they build when the platform fails them. See how we achieved 90%+ internal developer adoption while maintaining strict SOC2 compliance in our Cloud-Native Managed Platform Case Study. The goal is to make the platform good enough that developers choose it, not just comply with it.
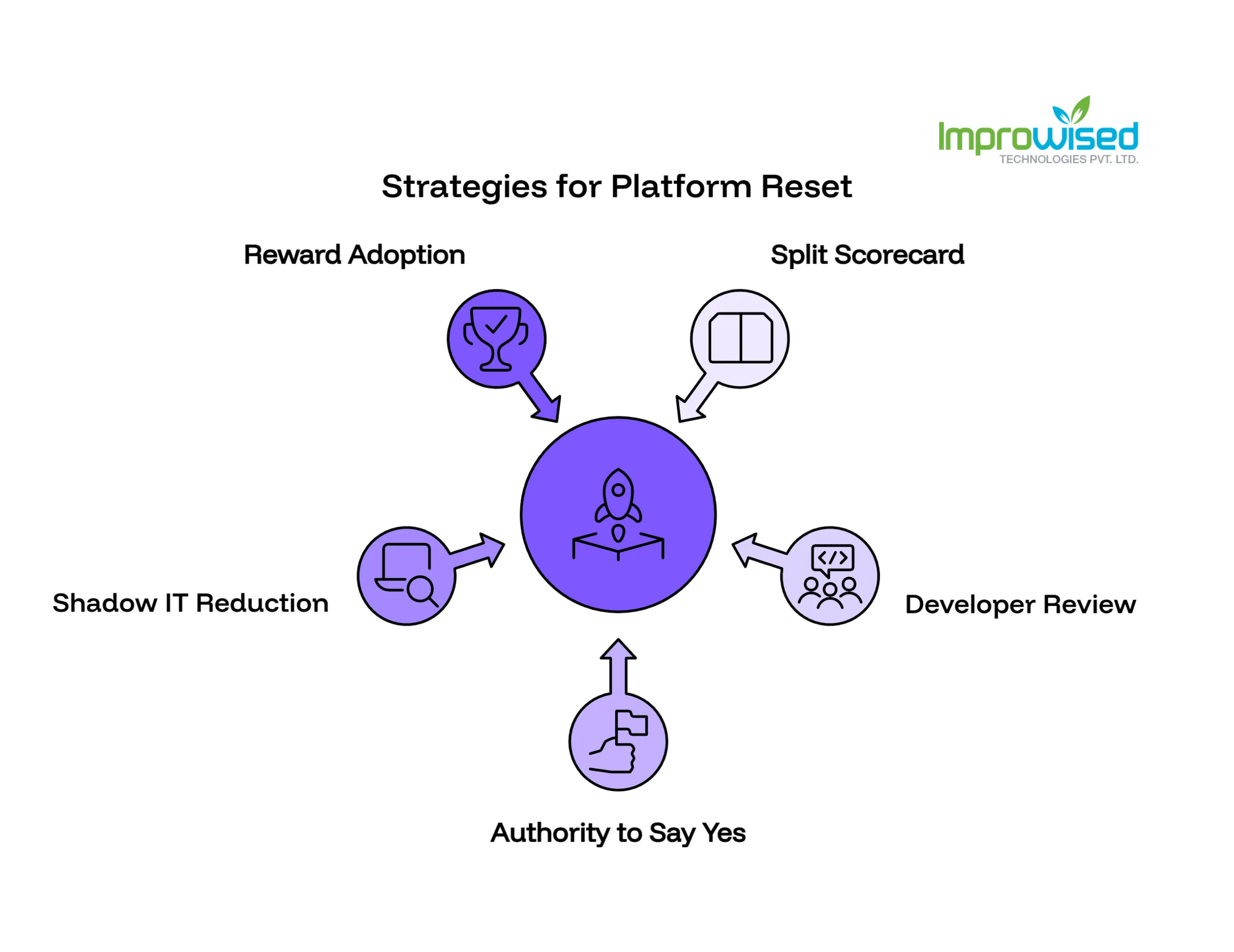
Here’s what a practical reset looks like:
Split the scorecard. Give the platform team a scorecard with two equal parts: reliability metrics (uptime, incident response, security audit pass rates) and adoption metrics (the ones listed above). Both sets of metrics matter. Neither can be ignored. This signals that reliability is still a priority, but it’s not the only priority.
Add a quarterly developer review. Not a survey, an actual structured review where platform team leads sit with a sample of their internal developer customers and walk through what’s working and what isn’t. This is a direct feedback loop that no ticketing system can replace.
Give platform teams the authority to say yes. A lot of platform friction comes from approval chains that sit outside the platform team. If the platform team has to route requests through security, legal, or architecture reviews for every non-standard request, they’ll be slow regardless of their intentions. Give them defined fast-path criteria to approve things themselves.
Measure shadow IT reduction as a goal. Set a target: reduce unmanaged production services by X% over the next two quarters. Assign that goal directly to the platform team. It connects their work to an organizational outcome that leadership cares about.
Reward adoption in performance reviews. This sounds obvious, but most platform engineers are reviewed on technical output, how many features they built, and how many incidents they handled. Start including adoption and developer satisfaction in individual performance criteria. Behavior follows measurement.
None of this requires dropping your reliability standards. It requires expanding what you hold the platform team accountable for.
The gap between platform investment and platform adoption is real, and it’s costing companies more than they realize, in duplicated infrastructure, security blind spots, and engineering time spent on workarounds instead of products.
The fix isn’t a new tool. It’s a different set of questions at the leadership level: Are developers actually using what we built? Are we making it easier or harder for them to do good work? And are we measuring the platform team on the outcomes that actually matter?
After 15 years of running these teams, I can tell you: the platform teams that answer those questions honestly are the ones that get adopted. The rest produce gatekeepers. If your platform team is inadvertently operating as the latter, let’s talk about how to fix your incentive loop.
Frequently Asked Question
Get quick answers to common queries. Explore our FAQs for helpful insights and solutions.
Shadow IT almost always starts with friction. When the official platform is slow, complicated, or requires too many approvals, developers find faster ways to get their work done. They spin up their own tools, use personal cloud accounts, or build workarounds. Over time, those workarounds become permanent production infrastructure that nobody is tracking or monitoring.
Track time to first deployment, self-service completion rate, repeat usage rate, and the percentage of production services that are actually running on the platform. These metrics tell you whether the platform is genuinely useful, not just technically stable. Uptime tells you the platform is running; adoption metrics tell you whether anyone actually wants to use it.
Because they're measured on things that reward caution, uptime, incident counts, and compliance. When those are your metrics, the safest behavior is to slow things down and add review steps. Friction becomes a side effect of self-preservation. The fix is adding adoption metrics to the scorecard so that being helpful to developers is also how the team succeeds.
Platform as a product means treating internal developers like customers. It works when the platform team is actually measured on developer satisfaction and adoption. It fails when the team adopts the language but keeps the same metrics, uptime, and compliance only. The label changes, the behavior doesn't.
Make the official platform faster and easier to use than the alternatives. If getting through your platform takes 2 weeks and a developer can set something up on their own in 2 days, they'll choose the 2-day option every time. Reduce approval steps, improve self-service documentation, and track how many production services are actually on the platform. Set a specific shadow IT reduction target and assign it to the platform team.
Written by
Hussain Gandhi
Hussain Gandhi is a DevOps Engineer at Improwised Technologies Pvt Ltd. He focuses on building scalable systems through automation and scripting. He has hands-on experience with cloud infrastructure, CI/CD pipelines, and infrastructure as code. Hussain combines strong technical skills with a collaborative work style. In his free time, he enjoys learning new things.


June 23, 2026
CI/CD, DevOps, or Platform Engineering, Which One Does Your Team Actually Need?
Divya Kathiriya
Author



June 18, 2026
The Real Cost of Tribal Knowledge: How to Audit and Eliminate Operational Risk
Chandan Teekinavar
Author



June 16, 2026
Why Your Developers Wait 3 Days to Set Up a Dev Environment
Chintan Viradiya
Author

Optimize Your Cloud. Cut Costs. Accelerate Performance.
Struggling with slow deployments and rising cloud costs?
Our tailored platform engineering solutions enhance efficiency, boost speed, and reduce expenses.