June 16, 2026
Why Your Developers Wait 3 Days to Set Up a Dev Environment

Chintan Viradiya
Author

Shyam Kapdi
Contributor

Shailesh Davara
Reviewer
You hired good engineers. They passed your interviews. They know their stuff.
And then their first week at your company? They spend most of it waiting.
Waiting for someone to share the right config file. Waiting for access to get approved. Waiting for the senior developer who “knows how everything is set up” to find a spare hour.
By day three, they’ve maybe written a few lines of code.
I’ve been in this industry for over 15 years, and I can tell you this: that’s not an onboarding problem. It’s a sign that your infrastructure has no self-service layer. Your team built the product, but they never built the system that lets people actually work on it without asking five different people for help.
What’s Actually Causing the Wait
When I talk to engineering leaders, they usually blame the documentation. “Our wiki is outdated.” Sure, that’s part of it. But the wiki is a symptom, not the cause.
Here’s what’s actually happening on the ground:
Every team has its own setup process. One team uses Docker in a certain way. Another team has a different .env file convention. Someone left six months ago and took the mental map of “how this all works” with them. There’s no single, standard way to spin up a working environment.
Dev, staging, and production don’t match. So even when someone finally gets their environment working, it often doesn’t behave the same way as what’s running in production. The old “works on my machine” problem is still very real, and it costs you debugging time every single week.
New hires have to chase people for credentials and access. This one I’ve seen at companies of all sizes. The new engineer needs access to four different systems, and each one requires a different person to approve it. Nobody has documented who owns what. The new hire spends their first week sending Slack messages and waiting for replies.
The setup guide is either missing or wrong. Most teams have some documentation. But it’s usually six months behind reality. Someone updated the deployment process, forgot to update the wiki, and now the guide has three steps that no longer apply and two steps that are missing entirely.
The result: every new hire reinvents the wheel, and at least one senior engineer loses a day or two helping them do it.
What Teams That Get This Right Do Differently
I’ve worked with teams that got new engineers writing real code on day one. Not a tutorial. Not a “hello world” exercise. Actual work.
Here’s what they did differently:
One command sets everything up. Not a 47-step wiki page. One command that pulls the environment, installs what’s needed, and has everything running in under an hour. The environment is defined in code, so it’s always current, always consistent, and it doesn’t depend on anyone’s memory.
Access gets provisioned automatically based on role. When a new backend engineer joins, the system knows what they need access to and handles it. No approval chains. No chasing people on Slack. The right access shows up because it’s built into the setup process.
The same environment definition is used everywhere. Dev, staging, and production all use the same base configuration. So when something works locally, it works everywhere. That one change alone eliminates a huge category of bugs and debugging time.
Nobody has to ask for help just to get started. The system handles it. People ask for help when they’re stuck on real problems, not on setup.
One company I’ll mention: a hospital management platform we worked with had a 3-day average onboarding time. After we built them a self-service platform, it dropped to same-day. The engineers didn’t get smarter overnight. The system just stopped requiring them to ask permission for everything.
The Cost Nobody Puts a Number On
Here’s a quick calculation that I think puts this in perspective.
Say you have 50 engineers and you hire two new people a month. If each new hire loses three days to setup, that’s six engineer-days per month. Over a year: 72 engineer-days. But that’s just the new hire’s time.
Count the senior engineers who stop what they’re doing to help. Add one day of senior time per hire. That’s another 24 engineer-days gone from your most expensive, hardest-to-replace people.
At a $100,000 average engineer salary, you’re looking at roughly $145,000 a year in pure setup overhead, and that’s for a 50-person team. Larger teams scale this problem up fast.
That number doesn’t include the time lost every time an existing engineer switches to a new project and has to figure out a new setup. Or the bugs that come from environment mismatches. Or the morale cost when a sharp new hire’s first experience with your company is bureaucratic and slow.
This is money that disappears quietly. Nobody writes it in a report. But it’s real.
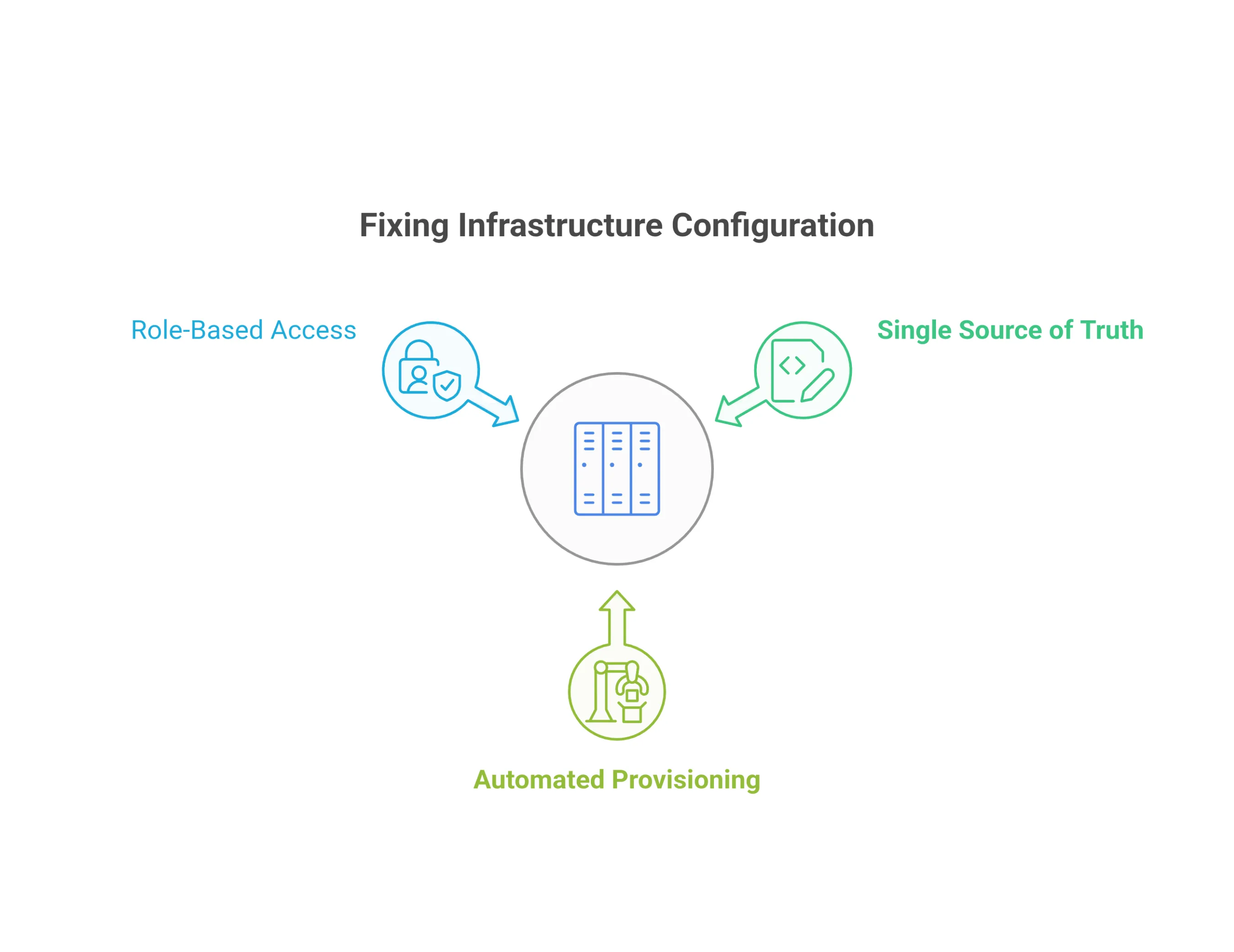
Three Things You Need to Fix It
You don’t need to rebuild your entire infrastructure. Most teams fix this in four to six weeks by focusing on three things:
1. A single source of truth for your environment config. Write your environments in code. Tools like Terraform or OpenTofu let you define exactly what an environment looks like, and reproduce it reliably. We wrote more on the security side of this in our piece on Infrastructure as Code best practices. The principle is the same: if it’s not in code, it’s in someone’s head, and that’s a problem waiting to happen.
2. Automated provisioning. One script or a simple portal that a new engineer runs on day one. It reads the environment definition, sets everything up, and provisions access based on their role. No human intervention required.
3. Role-based access built into the setup flow. Not bolted on after. Not a separate ticket to a separate team. When someone joins as a frontend engineer, the system knows what they need and gives it to them automatically. When someone leaves, access goes away the same way.
That’s it. Three things. Not a six-month project.
Where to Start
If you’re not sure where your setup currently stands, that’s actually the first thing to figure out. We built a five-minute platform maturity assessment that shows you exactly where your gaps are and what to fix first.
Most teams that go through it find two or three things they can fix quickly, without touching the rest of their infrastructure.
The goal isn’t perfection. It’s getting your engineers to do engineering work on day one instead of day four.
Frequently Asked Question
Get quick answers to common queries. Explore our FAQs for helpful insights and solutions.
The main reason is that most teams have no standard setup process. Each team does it differently, credentials require manual approval from multiple people, and the setup documentation is usually outdated. There's no automated system, so every new hire figures it out from scratch, with help from senior engineers who have other work to do.
A self-service developer platform lets engineers spin up their working environment, get credentials, and access the systems they need, without waiting on anyone else. Instead of chasing approvals, one command or a simple portal handles the whole setup automatically based on the engineer's role.
For a 50-engineer team hiring two people a month, slow onboarding costs around $145,000 a year in wasted engineer time, before counting the senior engineers who stop their own work to help. That number goes up with team size and doesn't include the bugs caused by inconsistent environments.
Dev is where engineers write and test code locally. Staging is a copy of production used for final testing before release. Production is what your users actually use. When all three don't match in configuration, code that works in dev breaks in staging or production, which is where most 'works on my machine' bugs come from.
Infrastructure as Code means writing your environment configuration in files using tools like Terraform or OpenTofu, instead of setting it up manually each time. When your environment is defined in code, anyone can reproduce it exactly. Set up stops depending on memory, tribal knowledge, or a person who may have left the company.
Most teams fix it in four to six weeks. The starting point is standardizing the environment definition, writing it in code so it's the same across dev, staging, and production. Automated provisioning and role-based access come after that. You don't need to rebuild your entire infrastructure to see results.
Role-based access provisioning means the system gives a new engineer exactly the access their role requires automatically, when they join. A backend engineer gets backend access. A frontend engineer gets frontend access. Nobody has to file a ticket or wait for approval. When someone leaves, that access is removed the same way.
DevOps focuses on how software gets built, tested, and deployed. Platform engineering builds the internal system, the tools, environments, and self-service layer that developers use every day to do that work. DevOps is the process; platform engineering is the infrastructure that makes the process fast and repeatable without requiring constant human coordination.
Written by
Chintan Viradiya
Chintan Viradiya is a DevOps Engineer at Improwised Technologies. Passionate about Infrastructure as Code and CI/CD pipelines, he focuses on optimizing cloud deployments and enhancing the security and performance of modern applications. He plays a key role in ensuring high availability and driving DevOps best practices across projects


June 18, 2026
The Real Cost of Tribal Knowledge: How to Audit and Eliminate Operational Risk
Chandan Teekinavar
Author


June 10, 2026
AI Hallucination in Production: What Your Monitoring Tools Are Missing
Hussain Gandhi
Author



June 6, 2026
Five Architecture Decisions That Eliminate Security Risk Before You Need a Tool
Chandan Teekinavar
Author
Optimize Your Cloud. Cut Costs. Accelerate Performance.
Struggling with slow deployments and rising cloud costs?
Our tailored platform engineering solutions enhance efficiency, boost speed, and reduce expenses.