June 18, 2026
The Real Cost of Tribal Knowledge: How to Audit and Eliminate Operational Risk

Chandan Teekinavar
Author

Shyam Kapdi
Contributor

Shailesh Davara
Reviewer
When operational knowledge lives in people instead of your platform, every resignation letter is a risk event. Every vacation is a gap. Every team reorganization is a guessing game.
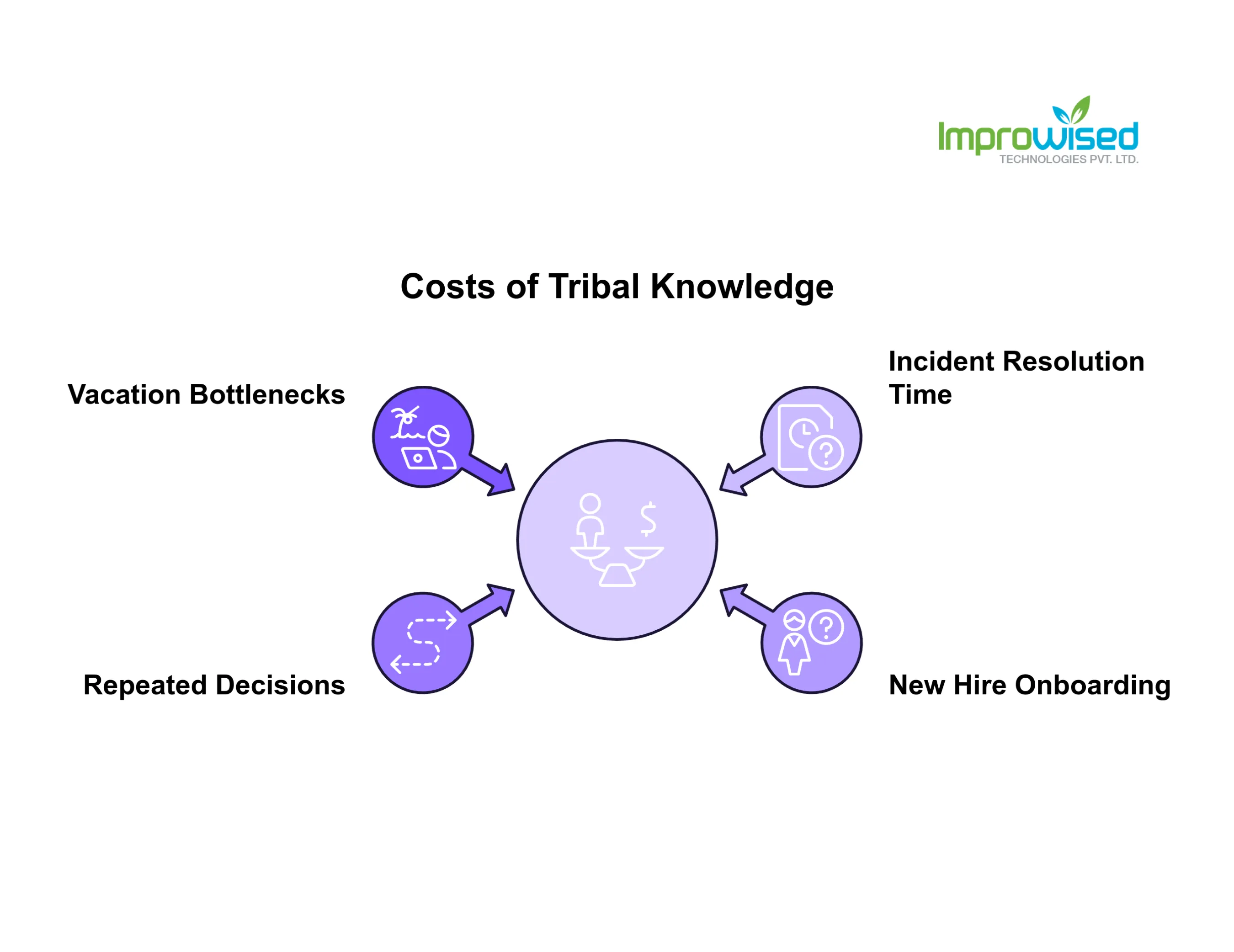
1. What Tribal Knowledge Actually Costs You
I’ve run engineering organizations for over 15 years. The most expensive problems I’ve dealt with were never in our infrastructure costs or vendor contracts. They were in what happened when a senior engineer left.
Not just the productivity dip. Not just the hiring cost. The real cost was discovering, three weeks later, that no one knew why a critical deployment process was done a certain way. Or that the person who left was the only one who understood how a particular integration actually worked in production.
Here’s what this looks like in practice across a 100-person engineering org:
-
Incidents take longer to resolve because the person who built the system isn’t there to explain it
-
New hires take 3–6 months longer to reach full output because they’re learning from whoever has time to explain things, not from the system itself
-
Decisions get repeated. Teams solve the same problems again because the last solution never got encoded anywhere
-
Vacations and time off create bottlenecks. People check Slack on PTO because they’re the only ones who know
The business cost isn’t always visible on a balance sheet, but it shows up in slower deployments, higher incident rates, and engineering capacity consumed by relearning things that were already figured out.
2. How to Audit Where Operational Knowledge Lives
Before you can fix this, you have to know where it lives. Most companies assume they have a documentation problem. They don’t. They have a knowledge location problem.
Run this audit with your team leads. It takes one conversation per team and about two hours total.
Ask four questions for each major operational area:
-
If this person were unavailable for two weeks, what would break or slow down?
-
Where is the decision-making logic for this process written down in a document, in code, or in someone’s head?
-
When something goes wrong here at 2 am, who does the team call? Why that person?
-
In the last 90 days, how many times did a decision get made by asking someone versus by following a defined path in the system?
Map your answers. You’ll see a pattern quickly. High-risk knowledge tends to cluster around your most senior engineers, your most complex integrations, and any process that was “temporarily” set up and never formalized.
The audit output isn’t a list of documents to write. It’s a list of platform behaviors that need to be built. If you want a structured way to measure how much of your infrastructure relies on human memory versus encoded systems, take our free Platform Engineering Maturity Assessment.
3. Documentation Is Not the Answer
I want to be direct about this because it’s where most companies waste time and money.
Documentation is a record. It tells someone what to do if they find it, read it, understand it, and remember it at the right moment. In a high-pressure operational situation, none of those four things is reliable.
When your on-call engineer is dealing with a production incident at midnight, they are not reading a Confluence page. They are following whatever the system shows them or calling whoever knows.
Encoded platform behavior is different. It means the system itself guides the action. The deployment pipeline enforces the correct steps. For a technical breakdown of how this works in practice, see our guide on encoding manual deployment knowledge by moving from Jenkins to GitOps with FluxCD. The alert routing is automatic. The rollback process is a button, not a procedure. The approval workflow is built into the tool, not described in a document.
The test for whether knowledge is truly encoded: Can a competent engineer who has never worked on this system before take the correct action without asking anyone or reading anything?
If the answer is no, you have tribal knowledge regardless of how much documentation exists.
4. How to Move Critical Knowledge Into the Platform
This is not a one-time project. It’s a shift in how your engineering organization thinks about operational work. This transition is exactly what we build for engineering teams through our Platform Engineering Services.
Start with the highest-risk items from your audit. For each one, ask: what would need to be true for this to be self-evident in the platform?
In practice, that usually means:
-
Deployment guardrails that encode the rules engineers currently carry in their heads, environment checks, dependency validations, and required approvals
-
Alert configurations that route to roles, not individuals, with runbooks embedded directly in the alert, not linked from it
-
Onboarding paths that are built into the development environment, not a Google Doc someone might have updated six months ago
-
Incident response workflows that walk the on-call engineer through steps in the tool, not in a separate tab
-
Access controls and environment boundaries that make the wrong action impossible, not just discouraged
The goal is to make the correct path the only path that’s easy to take. Not because engineers can’t be trusted, but because operational clarity should not depend on individual memory.
Prioritize the three or four areas where a wrong decision at 2 am causes the most damage. Start there. Build the platform behavior first. Then document what you built, not as an operational guide, but as a record of intent.
5. What a Knowledge-Resilient Platform Looks Like at 100+ Engineers
At scale, tribal knowledge risk compounds. You have more systems, more integrations, more operational surface area, and more people rotating through teams. What worked at 20 engineers will actively break at 100.
Here’s what I look for when assessing whether a platform-engineering organization has solved this:
Any engineer can handle any common incident without escalation. Not because they’ve memorized the runbook, but because the system walks them through it and has the context embedded.
New engineers reach operational confidence in weeks, not months. The platform tells them what they need to know at the moment they need to know it.
Senior engineers are not bottlenecks. Their knowledge lives in the system. They spend their time on new problems, not re-explaining solved ones.
Team changes do not create operational gaps. When someone leaves, transfers, or goes on leave, the system continues to function because the decisions live in the platform, not the person.
Post-incident reviews focus on system gaps, not individual gaps. When something breaks, the question isn’t “why didn’t the engineer know?” It’s “why didn’t the platform prevent or catch this?”
Reaching this state at 100+ engineers requires deliberate investment. It’s not free. (See how we encoded operational resilience at scale in our case study on building a Cloud-Native Managed Solution for a leading AI Platform). But the alternative, continuing to let operational knowledge accumulate in individuals, gets more expensive every quarter, especially in an environment where engineering turnover is not slowing down.
Conclusion
Tribal knowledge is not a documentation problem. It’s a platform design problem. The companies that figure this out stop losing operational capacity every time someone leaves, and start building organizations where the system itself carries the load.
The audit takes a day. The fix takes months of deliberate platform work. But every month you wait, the risk grows, and the next departure is one step closer. Contact us today to see how we can help you encode your tribal knowledge into a resilient, self-service internal developer platform.
Frequently Asked Question
Get quick answers to common queries. Explore our FAQs for helpful insights and solutions.
Tribal knowledge is operational information that exists in people's heads, not in your systems, documentation, or platform. It's the reason a senior engineer gets called at midnight, or why a team slows down for weeks after someone leaves. In engineering organizations, it typically builds up in deployment processes, incident response, system architecture decisions, and integration logic that was set up once and never formalized.
Because every person who holds critical operational knowledge is a single point of failure. When that person leaves, takes a vacation, or gets sick, the business absorbs the cost in slower incident resolution, longer onboarding, repeated mistakes, and engineering capacity spent re-learning things that were already figured out. With 100+ engineers, the compounding effect of this is significant.
Ask four questions for each major operational area: Who gets called when something breaks at 2 am, and why? What would slow down or break if your most senior engineer were unavailable for two weeks? Where does the decision-making logic for this process actually live in the system, or in someone's memory? In the last 90 days, how many times did a decision require asking a person versus following a defined path in the platform? Map the answers. High-risk knowledge clusters quickly become visible.
Documentation describes what to do. Encoded platform behavior makes the correct action the only easy option. Documentation requires someone to find it, read it, understand it, and remember it at the right moment. In a production incident at midnight, that chain breaks. Encoded platform behavior means the deployment pipeline enforces the correct steps, the alert includes the runbook, the rollback is a button, and the approval workflow is built into the tool. A competent engineer with no prior context can take the right action without asking anyone.
The audit typically takes one to two days across your team leads. Fixing the highest-risk areas takes months of deliberate platform work, not a weekend sprint. Most engineering organizations see meaningful risk reduction within one to two quarters if they prioritize the three to five areas where a wrong decision causes the most operational damage. The work is ongoing, not a one-time project.
The risk exists at any size, but it compounds significantly between 50 and 150 engineers. At this range, teams are large enough that knowledge cannot spread naturally through informal conversation, but small enough that formal platform investment is often deprioritized. Engineering turnover at this stage tends to create gaps that don't become visible until something breaks.
Written by
Chandan Teekinavar
Chandan Teekinavar is a DevOps Engineer at Improwised Technologies. Passionate about Infrastructure as Code and CI/CD pipelines, he focuses on optimizing cloud deployments and enhancing the security and performance of modern applications. He plays a key role in ensuring high availability and driving DevOps best practices across projects


June 16, 2026
Why Your Developers Wait 3 Days to Set Up a Dev Environment
Chintan Viradiya
Author


June 10, 2026
AI Hallucination in Production: What Your Monitoring Tools Are Missing
Hussain Gandhi
Author



June 6, 2026
Five Architecture Decisions That Eliminate Security Risk Before You Need a Tool
Chandan Teekinavar
Author
Optimize Your Cloud. Cut Costs. Accelerate Performance.
Struggling with slow deployments and rising cloud costs?
Our tailored platform engineering solutions enhance efficiency, boost speed, and reduce expenses.