May 26, 2026
Stop Burning Cash on AI Tokens And Start Tracking What Matters

Shailesh Davara
Author

Shyam Kapdi
Contributor

Rakshit Menpara
Reviewer
Your AI is running. That does not mean it is working.
My senior called me last quarter. He had one question: why did our cloud bill go up 40% when our product revenue stayed flat?
I did not have a clean answer. And that bothered me more than the bill itself.
I have been building and running cloud infrastructure businesses for over 15 years. I have seen every kind of cost blowout: idle servers, over-provisioned databases, runaway data transfer fees. But what is happening right now with AI spending is different. It is quieter. It is harder to see. And it compounds fast.
Your Cloud Bill Went Up. Your Revenue Did Not. Here’s Why.
Here is the situation most companies are walking into right now.
You added an AI feature. Your team is excited. The demo works. You ship it. A few weeks later, your cloud invoice has a new line item with a number that makes you pause.
You ask your engineering team what happened. They say the AI is working fine. No errors. No outages. Uptime is 99.9%.
But nobody can tell you how much it costs to answer one customer question. Nobody can tell you how many of those questions actually got answered well. Nobody can tell you whether the AI went in circles three times before giving up, and you paid for all three attempts.
That is the problem. We built monitoring for servers. We did not build monitoring for thinking.
Traditional Monitoring Only Tells You If the Server Is On
Standard infrastructure monitoring tells you if something is on or off. Is the server running? Did the API call go through? Did the response come back within the time limit?
That is useful. But it tells you nothing about whether the AI did anything valuable.
Think about it this way. You have a customer support agent powered by AI. A user sends a message. The AI receives it, runs a series of internal steps, calls a few tools, generates a response, and sends it back. The server never went down. The response time was fine. Everything looks green on your dashboard.
But what if the AI misunderstood the question, searched the wrong database twice, generated a response that did not help, and the user left without their problem solved?
You paid for all of that. Every token in. Every token is out. Every tool call. And you got zero business value in return.
Your monitoring system did not catch it. Because it was never designed to.
Why Your AI Bill Keeps Rising, And Nobody Can Explain It
Tokens are the unit of measurement for AI work. Every word the AI reads and every word it writes costs tokens. Tokens cost money.
When a custom Autonomous Agent is efficiently engineered for multi-step work, reading a document, deciding what to do, calling a tool, checking the result, deciding what to do next, each one of those steps burns tokens. If the agent gets confused, it loops. If it loops, you pay again. And again.
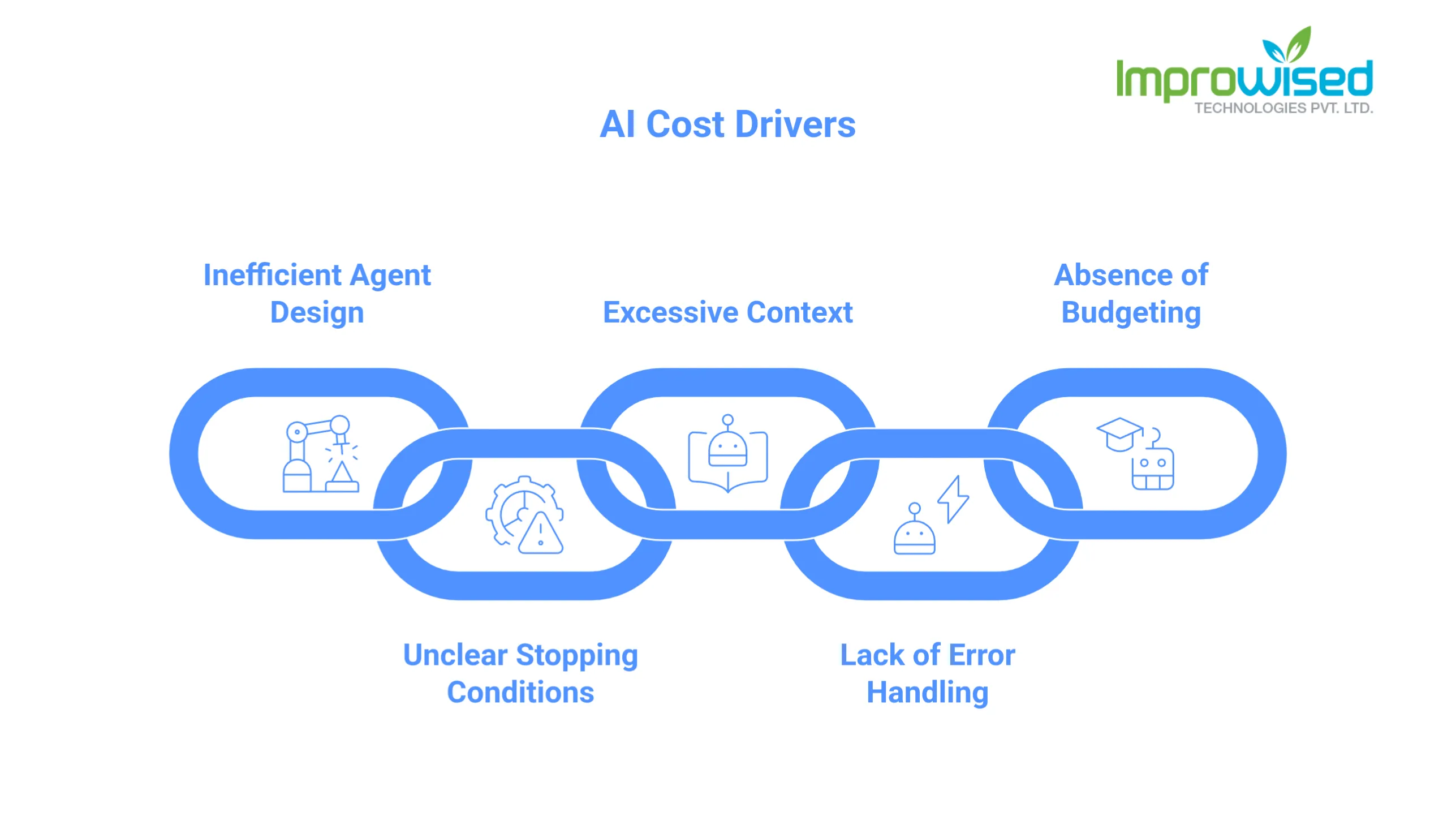
Here are the patterns I see burning money in most AI deployments:
-
The AI tries the same thing three times because it did not understand the first result
-
A prompt is written without a clear stopping condition, so the agent keeps going until it hits a token limit
-
The AI is given too much context; it does not need massive documents, full conversation histories, because nobody trimmed what gets sent in
-
Error handling is not built in, so when something goes wrong, the system retries automatically and charges you for each attempt
-
Nobody set a budget per query, so one confused user interaction can cost 50x what a normal one costs
None of these show up as an outage. None of them triggers an alert. They just quietly eat your budget.
What You Need to Measure Before the Next Board Meeting
This is not a technology problem. It is a measurement problem.
You would never run a sales team without tracking cost per lead and revenue per deal. You would never run a warehouse without tracking the cost per shipment. But most companies are running AI features without tracking cost per interaction.
Here is what needs to be visible to you as a leader:
-
How much did this specific user interaction cost in API tokens?
-
Did the AI complete the task, or did it fail or give up?
-
How many steps did it take to get there?
-
What is the average cost per successful outcome versus a failed outcome?
-
Which types of queries are cheap and work well, and which are expensive and often fail?
With this information, you can make decisions. You can fix the expensive failures. You can optimize the prompts. You can set limits. You can prioritize which AI features actually earn their cost.
Without it, you are flying without instruments.
Every AI Dollar Needs to Map to a Business Outcome
This is the shift that changes everything.
Right now, most AI cost reporting looks like this: here is how many tokens we used this month. Here is what we paid.
What it needs to look like is this: here is what each customer interaction costs us in compute. Here is what that interaction produced. Here is the cost per successful resolution, per completed transaction, per answered question.
If a customer query costs $0.10 in API calls and generates value for the business, that is a working feature. If it costs $0.10 and generates nothing, that is a liability you are scaling.
The question is not whether AI is expensive. It is whether what you are spending is producing anything.
Every platform engineering team I have worked with over the last 15 years has found savings when they started measuring the right things. AI is no different. The waste is there. It is just invisible until you look for it.
Three Things to Do Before Your Next Cloud Invoice Arrives
You do not need to rebuild your entire infrastructure to start getting visibility. You need to add a layer of tracking that most AI deployments skip.
At a minimum, you want to capture three things for every AI interaction:
-
The cost: how many tokens were consumed, and what that translates to in dollars
-
The outcome: did the task complete, fail, or time out
-
The path: how many steps did it take, did it loop, did it retry
Once you have that data, patterns will surface quickly… Fix those, and the cloud bill drops just as we’ve seen with leading AI orchestration platforms.
The next step is setting limits. If a single customer interaction should cost no more than a certain amount to serve, build that constraint into the system. When the AI hits that limit, it should stop and return what it has, and not keep going and charge you for the excess.
This is basic financial control applied to a new kind of compute. It is not complicated. It just has not been standard practice yet.
Where to Start
If your finance team is asking questions about AI spend that your engineering team cannot answer, that is your signal.
It does not mean your team is doing something wrong. It means the tooling that exists today was built for a different era. API uptime monitoring was designed for services that either work or do not. AI agents operate differently; they can be running perfectly and still be wasteful, confused, or produce nothing useful.
Start by mapping your current AI usage. Identify every place in your product where an AI model is being called. For each one, answer these questions: what does success look like, what does failure look like, and what does it cost per interaction?
If you cannot answer those three questions today, that is where the work starts.
The companies that get ahead on AI cost efficiency in the next 18 months will not be the ones with the most advanced models. They will be the ones who know exactly what they are spending and exactly what they are getting for it.
That is a discipline. And it is one worth building now.
If your finance team is asking questions about cloud spend that your engineering team cannot answer, it is time to map your AI usage.
Let’s look at your architecture and find where the waste is. No pitch. Just a look at the numbers.
Frequently Asked Question
Get quick answers to common queries. Explore our FAQs for helpful insights and solutions.
Your cloud bill is likely increasing because AI token consumption compounds invisibly. When an Autonomous Agent processes multi-step work, every word it reads and writes costs money. If the agent gets confused, loops continuously, or processes massive, untrimmed context windows without clear stopping conditions, you pay for every retry. The AI functions perfectly from an uptime perspective while quietly burning through your budget.
Traditional infrastructure monitoring is built to track API uptime, server health, and response times. It tells you if a system is 'on,' but not if it is operating efficiently. An AI feature can show 99.9% uptime on a dashboard while simultaneously wasting compute by searching the wrong databases, looping through failed prompts, and abandoning unresolved customer queries. You need monitoring built for 'thinking,' not just for servers.
High AI compute costs usually stem from four invisible architectural inefficiencies:
- The AI loops and tries the same failed action multiple times.
- Prompts lack clear stopping conditions, causing the agent to run until it hits a hard token limit.
- The system is fed untrimmed context (like massive documents or full conversation histories) that it doesn't actually need.
- Automatic error handling triggers endless retries, charging you for every single automated attempt.
To stop flying blind, you must stop looking at bulk monthly token usage and instead capture three specific data points for every single AI interaction:
- The Cost: The exact number of API tokens consumed and their dollar equivalent per query.
- The Outcome: Whether the specific task was completed successfully, failed, or timed out.
- The Path: The number of steps, loops, or retries the AI took to get to that outcome.
You must shift from reporting overall token usage to tracking the exact cost per interaction. Calculate what it costs in compute to achieve a successful resolution, a completed transaction, or a helpful answer. If a query costs $0.10 in API calls and solves a user's problem, that is a working feature. If it costs $0.10 and generates no business value, it is a scaling liability that requires immediate optimization.
Apply basic financial controls directly to your new compute layers by setting a tight budget per query. Define the maximum acceptable cost to serve a specific customer interaction. Build constraints into your architecture so that if the AI hits that token limit, it immediately stops and returns what it has, preventing it from looping and charging you for excess compute.
July 16, 2026
What a DevSecOps Architecture Actually Looks Like (Not the Diagram, the Real Thing)
Hussain Gandhi
Author



July 6, 2026
Migration Debt: Why Unfinished Migrations Are Your Most Expensive Technical Debt
Chandan Teekinavar
Author



June 30, 2026
Your AI Bill Is Going Up. Your Output Isn't. Here's Why.
Chintan Viradiya
Author

Optimize Your Cloud. Cut Costs. Accelerate Performance.
Struggling with slow deployments and rising cloud costs?
Our platform engineering solutions are built on open-source tools and use AI natively across the workflow.