May 21, 2026
Why Your Deployment Frequency Is Slowing Down

Chintan Viradiya
Author

Shyam Kapdi
Contributor

Shailesh Davara
Reviewer
Nobody woke up one morning and decided to make software releases slower. There was no meeting where someone said, “Let’s add three more weeks to every deployment.” And yet, here we are, teams that used to ship weekly now shipping monthly. Teams that shipped monthly are now shipping quarterly. And nobody can point to the decision that caused it.
This is the pattern I’ve seen repeat across companies for fifteen years. The slowdown doesn’t arrive with a warning. It compounds quietly, one sensible addition at a time.
1. How Release Cycles Slow Down Without Anyone Noticing
Every step added to a release process has a reason. A production incident happens, so a new review step gets added. A compliance requirement comes in, so a sign-off is now required. A bug slips through, so a second staging environment gets introduced.
Each of these additions, taken alone, makes complete sense. Nobody argues against the step when it’s proposed. So it goes in.
The problem is that nobody is tracking what happens when you stack ten of these additions on top of each other over two years. A release that used to take two days now takes two weeks, and the team has adapted so gradually that it feels normal. When I ask engineering leaders how long their release cycle takes, the common answer is: ‘It’s complicated.’ That answer tells me everything.
When your team can’t give you a simple number, the process has already grown beyond what anyone fully understands.
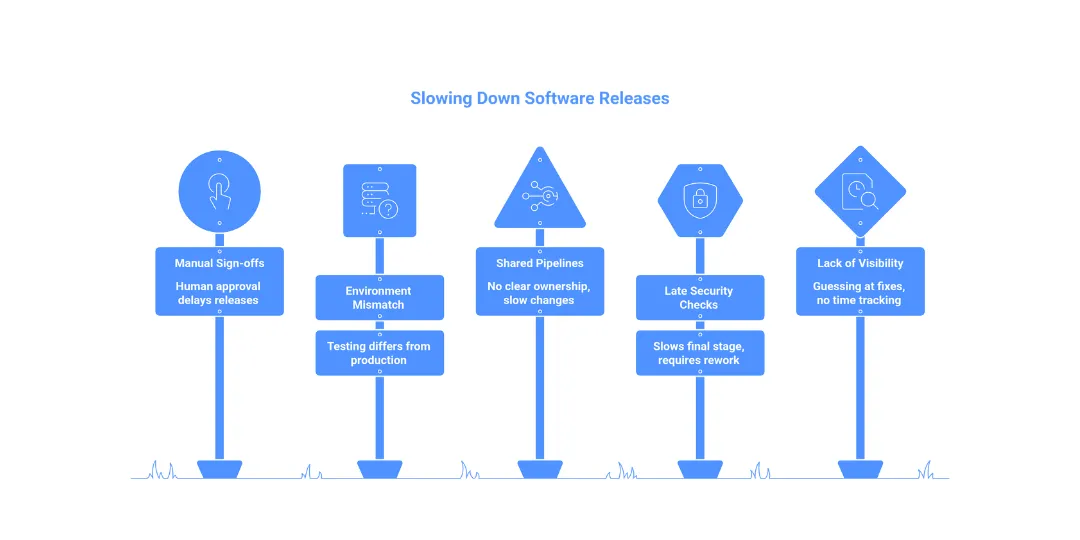
2. The Five Most Common Sources of Hidden Pipeline Friction
After working with dozens of engineering organisations, these five things show up almost every time:
- Waiting for humans to approve what machines could check.
Manual sign-offs between pipeline stages. Someone has to look at a dashboard and click a button, but they’re in a meeting, on leave, or they just haven’t gotten to it yet.
- Environments that don’t match production.
Testing in a staging environment that behaves differently from the live system. Teams catch it after the deployment, not before.
- Shared pipelines with no clear ownership.
When everyone’s release goes through the same system, and nobody owns it, changes are slow. This is a classic symptom of failing to separate CI and CD pipelines anything that breaks affects everyone.
- Security and compliance checks bolted on at the end.
These checks get added after the build is done because that’s the only place available. They slow the final stage and often require going back to the beginning.
- No visibility into where time actually goes.
Teams measure total cycle time but not where the time is spent. Without that, you’re guessing at fixes.
None of these is dramatic on its own. Together, they can turn a two-day release into a two-week one.
3. Why Manual Approval Gates Point to a System Problem, Not a Quality Standard
This is the one that surprises people most when I say it.
When a team needs a human to manually approve a deployment, they are telling you unintentionally that their system cannot verify its own output. The approval gate exists because the team doesn’t have enough automated checks to trust the result without a person double-checking it.
I’m not saying quality reviews don’t matter. I’m saying that if quality review means a person sitting down and manually scanning a deployment checklist before clicking “approve,” you have a gap in your system, not a quality standard.
Manual gates are often added after something went wrong. They feel responsible. And in the short term, they reduce errors. But they also add hours or days to every release that follows, indefinitely. Over time, the cost of those gates far exceeds the cost of the original problem they were meant to prevent.
The right response to a production incident is not to add a gate. It’s to understand why the system didn’t catch it automatically, and fix that.
4. How to Diagnose a Deployment Slowdown as an Architecture Problem
Most companies try to fix deployment speed with process changes: new tools, better planning, tighter sprints. These help for a quarter or two, and then the numbers regress. I’ve watched this cycle happen at company after company.
The reason process changes don’t hold is that the underlying architecture hasn’t changed. You’re trying to run faster on the same road. The road is the problem.
Here’s how I approach the diagnosis:
-
Map the full release path from code commit to production. Most teams haven’t actually done this end-to-end. When you draw it out, you’ll find waiting time that nobody knew existed.
-
Separate active time from waiting time. Code being reviewed, tested, or deployed is active time. Code sitting in a queue waiting for approval or for an environment to be free is waiting time. In most pipelines I’ve audited, waiting time is 60–80% of total cycle time.
-
Look at what fails most often. If the same stage fails repeatedly, the system doesn’t trust what came before it. That’s an architecture signal.
-
Ask how many teams are blocked by a shared dependency. Shared infrastructure, shared pipelines, shared approval owners, and any shared dependency become a bottleneck as the team grows.
If your DORA metrics are poor but your process looks fine on paper, an expert platform engineering audit will show you exactly where the architecture is fighting the process.
5. What a Fast Delivery System Actually Looks Like at 50+ Engineers
At small team sizes, say, under 20 engineers, almost any setup can work. People know each other, communication fills the gaps, and informal processes hold things together.
Past 50 engineers, informal stops working. The gaps that people used to fill with conversations become delays that nobody owns. This is when architecture starts to determine speed, not people, not process, not tools.
The teams I’ve seen consistently ship fast at 50, 100, 200+ engineers share a few things:
- Teams own their own deployment path.
Each team can deploy its own service without waiting on another team’s pipeline, approval chain, or infrastructure.
- Checks run automatically, in the right order.
As we’ve demonstrated in our GitOps transformation case studies, security checks, performance checks, and test coverage should all be built into the pipeline to run before any human sees the result.
- Failure is expected and handled.
The pipeline assumes things will go wrong and has a clear rollback path. Teams don’t fear deploying because a bad deployment can be reversed quickly.
- Release frequency is treated as a system metric, not a team behaviour.
When deployment frequency drops, the first question is: what changed in the system? Not: what did the team do wrong?
Conclusion
Deployment slowdowns are not a people problem. They are not a process problem. They are a system design problem that shows up as a people and process problem.
Every manual gate, every shared bottleneck, every check added at the end of the pipeline instead of the beginning, these are symptoms. The underlying condition is a delivery architecture that was designed for a smaller team and a simpler product, and was never updated as either grew.
Measuring DORA metrics without fixing the architecture is like measuring your blood pressure every morning without changing what’s causing it to be high. You get good data on a problem that isn’t getting better.
If your team is shipping slower than they were two years ago, and nothing dramatic happened to cause it, the answer is almost certainly compounding friction in the system, not effort or capability in the team. Contact Improwised today to map your delivery architecture and get your deployment frequency back on track.
Frequently Asked Question
Get quick answers to common queries. Explore our FAQs for helpful insights and solutions.
Deployment frequency slows down when release processes accumulate manual approvals, shared dependencies, and additional checks without redesigning the delivery architecture.
Common causes include manual approval gates, inconsistent environments, shared pipelines, delayed security checks, and a lack of visibility into waiting time.
Manual approvals indicate that the system cannot automatically validate deployment safety, creating delays and bottlenecks as team size increases.
Shared pipelines create dependencies between teams, so failures, maintenance, or approval delays in one workflow affect unrelated deployments.
Staging environments frequently differ from production in scale, configuration, or dependencies, making test results unreliable for real deployment behavior.
Teams should map the full release path, separate active work from waiting time, and measure where deployments spend the most time in queues or approvals.
Deployment speed depends on how pipelines, environments, and dependencies are designed, not just on team process or tooling choices.
Written by
Chintan Viradiya
Chintan Viradiya is a DevOps Engineer at Improwised Technologies. Passionate about Infrastructure as Code and CI/CD pipelines, he focuses on optimizing cloud deployments and enhancing the security and performance of modern applications. He plays a key role in ensuring high availability and driving DevOps best practices across projects
July 16, 2026
What a DevSecOps Architecture Actually Looks Like (Not the Diagram, the Real Thing)
Hussain Gandhi
Author



July 6, 2026
Migration Debt: Why Unfinished Migrations Are Your Most Expensive Technical Debt
Chandan Teekinavar
Author



June 30, 2026
Your AI Bill Is Going Up. Your Output Isn't. Here's Why.
Chintan Viradiya
Author
Optimize Your Cloud. Cut Costs. Accelerate Performance.
Struggling with slow deployments and rising cloud costs?
Our platform engineering solutions are built on open-source tools and use AI natively across the workflow.